Categories#
Refers to a group of Documents which can be extracted by one Extraction AI. Per Projects, there can be multiple Categories.
Add a Category#
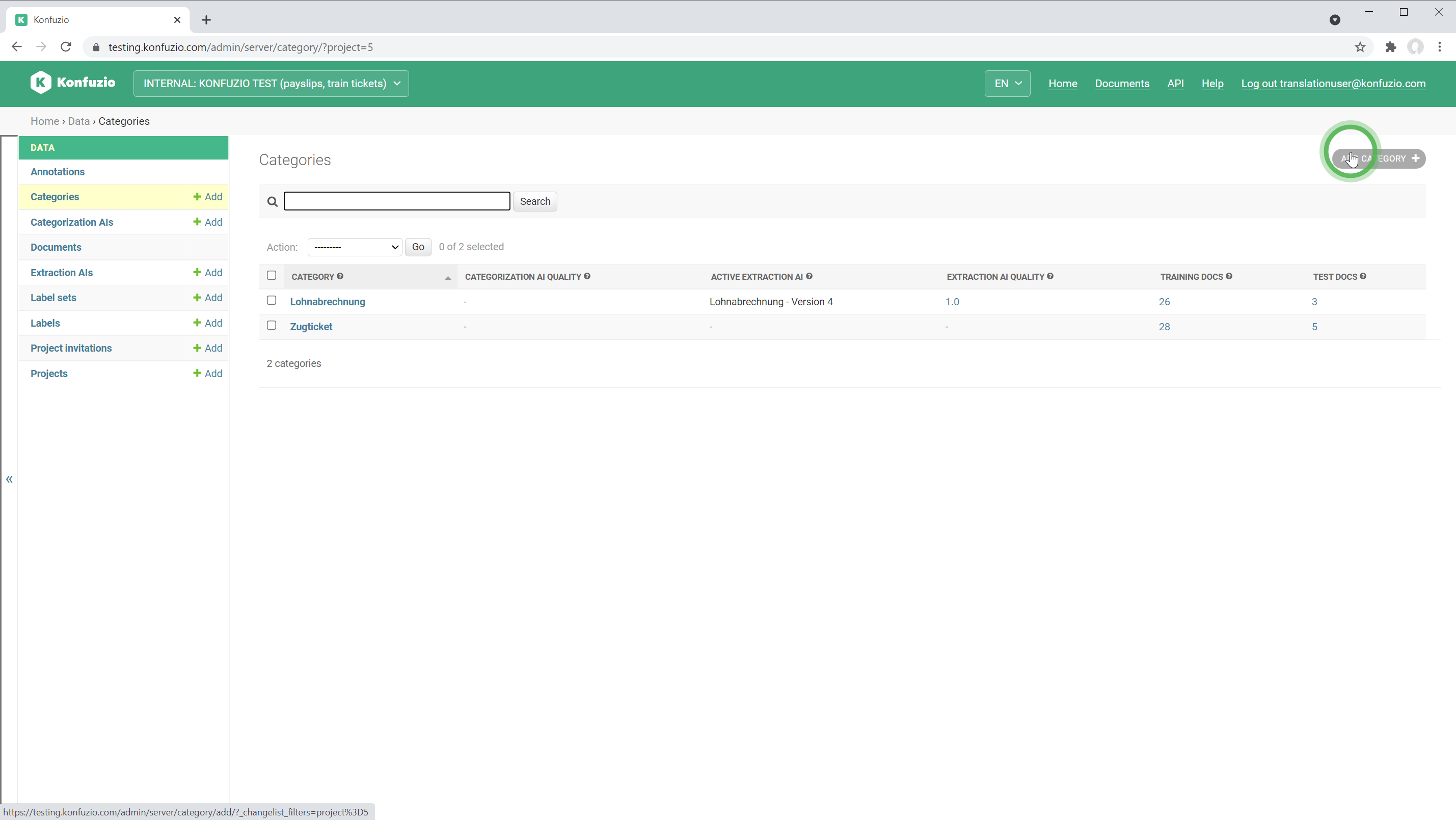
Category details#

Name#
Verbose name of the Category.
API Name#
Technical name of the Category used in the REST API.
Description#
A short description of the Category. We highly recommend using it. Even though the description seems to be trivial, it helps to share knowledge between users.
Active Extraction AI#
The Extraction AI is used for all Documents classified as the respective Category.
Detection mode of Extraction AI#
Level of granularity the Extraction AI will be trained on. It defines the smallest element the Extraction AI of this Category can operate on.
Character#
Use the character option in case the text you want to extract is within one word, as marked in the SmartView.

Word#
The smallest element will be one word as marked in the SmartView.
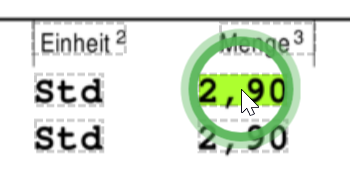
Multiple words can be connected.

Sentence (Beta)#
A full sentence is marked.

Paragraph (Beta)#
A computer vision approach will detect Paragraphs.
Extraction AI parameters#

There are advanced configurations of the training of the Extraction AI that you can adjust to achieve a better fitting for your case.
These configurations allow generating features that may help your Extraction AI to better identify the entities that you aim to detect such as specific names or dates. These entities will be learned based on your Annotations. The Extraction AI will get the text of the Document, look through the words that you annotated and learn the features associated with them. You can extend these features by specifying helpful words/expressions or the number of neighboring words that the Extraction AI should consider when evaluating a word(s) in the Document. The configurations that you can specify are:
n_nearest: look for n words in the neighborhood
n_nearest_across_lines: look for the neighbors also across lines
use_separate_labels: considers Labels shared by Label Sets as different Labels
strict_evaluation: modify the behaviour of the evaluation process to evaluate on a character exact level
n_estimators: modify the number of trees in the algorithm behind the Extraction AI. Higher number leads to a better but slower performance.
max_depth: modify a condition to stop going deeper by the decision tree in the algorithm behind the Labels Classifier which mainly classifies words into different Labels. Higher number leads to a better but slower performance.
label_set_max_depth: modify a condition to stop going deeper by the decision tree in the algorithm behind the Label Sets Classifier which is behind the decision if a certain Label belongs to a certain Annotation Set. Higher number leads to a better but slower performance.
label_set_n_estimators: modify the number of trees in the algorithm behind the Label Sets Classifier. Higher number leads to a better but slower performance.
label_set_n_nearest_template: look for n lines in the neighborhood to be processed by Label Set Classifier. A lower number works better with Annotation Sets that are spread over one to few lines (For example, invoice items which occupy one to few lines of a document ). A higher number works better with Annotation Sets that are spread over many lines (For example, information that are spread over a whole page and that all belong to the same Annotation Set).
You can adjust them in the field “Extraction AI parameters” of the Category view. They must be a valid JSON.
N nearest#
Use this feature if you think that providing more context can help to detect the entities that you want to identify.
In the “Extraction AI parameters” field, pass the number of neighboring words to consider as an int or a list with the key ‘n_nearest’. If you pass a list, the first number is considered the number of words to consider to the left and the second, the number of words to consider to the right. If you pass an int the same number of words are considered to the left and to the right. By default, the Extraction AI considers 2 words to the left and to the right.
{
"n_nearest": [
2,
2
]
}
The way it works is:
For each Annotation, it gets all left and right neighbors that are on the same line.
Being “n_nearest”: [l, r], the l closest neighbors to the left and the r closest neighbors to the right are selected.
For each of those neighbors, the offset string and the distance between the Annotation and the neighbor are added as features.
The distance is calculated as follows:
for left neighbors: annotation.x0 - neighbor[‘x1’]
for right neighbors: neighbor[‘x0’] - annotation.x1If there are less than l and r neighbors, “fake” neighbors are added to reach the specified number.
The “fake” neighbors have an empty offset string (“”) and a distance to the Annotation of 100000.For each of the selected neighbors, the same features as the ones used for the Annotation are also added.
Restrictions#
It only checks for neighboring words on the same text line.
N nearest across lines#
Use this feature if the neighboring words should also be considered across the text lines. It completes the “n nearest” feature by searching for neighbors in other lines than the one where the Annotation is.
For example, if an entity that you want to identify normally has a word on the line that precedes it. Or, in case where aren’t many words in the lines of the Annotations, instead of adding “fake” neighbors, they are collected from the previous and next lines.
In the “Extraction AI parameters” field, pass the boolean variable “true” with the key ‘n_nearest_across_lines’. By default, the neighboring words are not considered across lines.
{
"n_nearest_across_lines": true
}
The way it works is:
For each Annotation, checks the previous lines (line by line), starting from the line where the Annotation is.
For each word in that line, gets the minimum distance of the x coordinates between the Annotation and the word.
For each of those words, the offset string and the distance between the coordinates of the Annotation and the word are added as features, as well as the distance in lines to the Annotation.
It stops checking the lines when the number of neighboring words is equal or superior to the specified number of left neighbors.
If the Annotation has no left neighbors in its line, the limit is defined by the specified value for the left neighbors.
If the annotation has many left neighbors in its line, no words from the previous lines will be considered.
The same process happens for the right neighbors but the lines to be verified are those that are after the line where the Annotation is.
Restrictions#
The number of neighboring words across lines is limited by the “n_nearest” parameter.
Tokenizer mode#
If the detection mode is set to “Paragraph” or “Sentence”, you can also set the
tokenizer_mode parameter to either detectron (the default) or line_distance:
{
"tokenizer_mode": "line_distance"
}
See the SDK documentation for details.
Separate Labels#
Use this feature if you have Labels shared by different Label Sets and the results of the Extraction AI are not having the correct Label Set assigned.
For example, let’s consider that one wants to identify the surname of the sender and the surname of the receiver in invoices. There is a Label “Surname” associated with the Label Set “Sender” and also associated with the Label Set “Receiver”. However, after retraining an Extraction AI, the results are identifying the surname of the sender as if it was from the receiver. We can use this feature to help the distinction.
In the “Extraction AI parameters” field, pass the boolean variable “true” with the key ‘separate_labels’. By default, the separation does not occur.
{
"separate_labels": true
}
The way it works is:
For each Annotation, we get the name of the Label and the name of the Label Set where it’s associated. For example, “Surname” from “Sender”.
A new Label is created with the new name defined based on the name of the Label and Label Set collected. For example, “Sender__Surname”.
If the Label already exists, this step is skipped.The annotation is associated with this new Label.
In the extraction step, the label set name is extracted from the resulting Label and the Label name is rewritten to its original version. For example, the result with the Label “Receiver__Surname” will correspond to a result with the Label “Surname” in the Label Set “Receiver”.
Labels associated to the Label Set used as Category will not be rewritten.
N Estimators#
Use this feature if you are not satisfied with Extraction AI’s ability to generalize. Default value is 100.
The n_estimators controls the complexity and robustness of the model. A higher value for n_estimators leads to a
better generalization performance, as it reduces the impact of individual noisy predictions. However, increasing
n_estimators is also more computationally expensive.
{
"n_estimators": 150
}
Max depth#
Use this feature if you are not satisfied with the Extraction AI’s ability to pick up more complex / less occurring patterns. Default value is 100.
The max_depth influences the model’s ability to capture intricate patterns in the data. A higher max_depth has to
be picked with attention as it can lead to overfitting. A lower max_depth may result in underfitting and reduced
overall performance.
{
"max_depth": 120
}
Label Set Max Depth#
This feature helps the Label Set Classifier recognize more complex patterns in your data. By adjusting the label_set_max_depth, you control how deeply the classifier looks for these patterns.
The default value for label_set_max_depth is 100, but you can increase it if you want the classifier to find more detailed patterns. Just be careful not to set it too high, as that might make it focus too much on small details and not the big picture. Setting it too low might make it miss important patterns altogether.
{
"label_set_max_depth": 120
}
Label Set N Estimators#
Use this feature if you are not satisfied with the Label Set Classifier’s ability to generalize. Default value is 100.
This feature affects how confident the Label Set Classifier is in its predictions.
The label_set_n_estimators parameter determines how many different “opinions” the classifier gets before making a decision. By default, it gets 100 opinions, but you can change that if you want it to be more or less confident. Having more opinions generally means it’s more sure of its decision, but it also takes longer to make up its mind which makes it more computationally expensive.
{
"label_set_n_estimators": 150
}
Label Set N Nearest Template#
Use this feature if you want to consider more or fewer lines in the neighborhood to be processed by the Label Set Classifier. Default value is 5.
The label_set_n_nearest_template influences the number of lines in the neighborhood to be processed by the Label Set Classifier. A lower label_set_n_nearest_template narrows down the model’s scope of attnetion to few sentences which works better with Annotation Sets that are spread over one to few lines. A higher label_set_n_nearest_template gives the model a bigger picture and works better with Annotation Sets that are spread over many lines.
{
"label_set_n_nearest_template": 1
}
Removed Extraction AI parameters#
Each version of Konfuzio adds new features and functionality. Occasionally, new versions also remove features and functionality, often because they’ve added a newer option. This section provides details about the Extraction AI Parameters that have been removed in Konfuzio, and which won’t be available for newly trained AIs. Note that your existing Extraction AIs will not be affected and will remain functional.
The removed configurations are:
Extraction AI parameter |
Details |
Support removed |
|---|---|---|
catchphrase features |
look for the distance in lines from the word being evaluated to the specified expressions |
April 1st, 2023 |
substring features |
look for the existence of certain words(s) on the page |
April 1st, 2023 |
Links#
Review the Label Set of the Category in detail. Also see Label Sets.
Extraction Evaluation for active Extraction AIs#
Summarizes the AI quality of corresponding Label Set.
