Documents#
A Document refers to a file uploaded to Konfuzio Server, see supported file types.
Upload new Documents#
Drag and drop or browse your local files and wait until the link to the Document shows up.
Check the supported file types and languages.
You can also upload new Documents via our REST API or by email.
More detailed information about uploading new documents
Delete Document#
Select Document(s) you want to delete. Select “Delete documents” and press GO to verify your action on the next page.
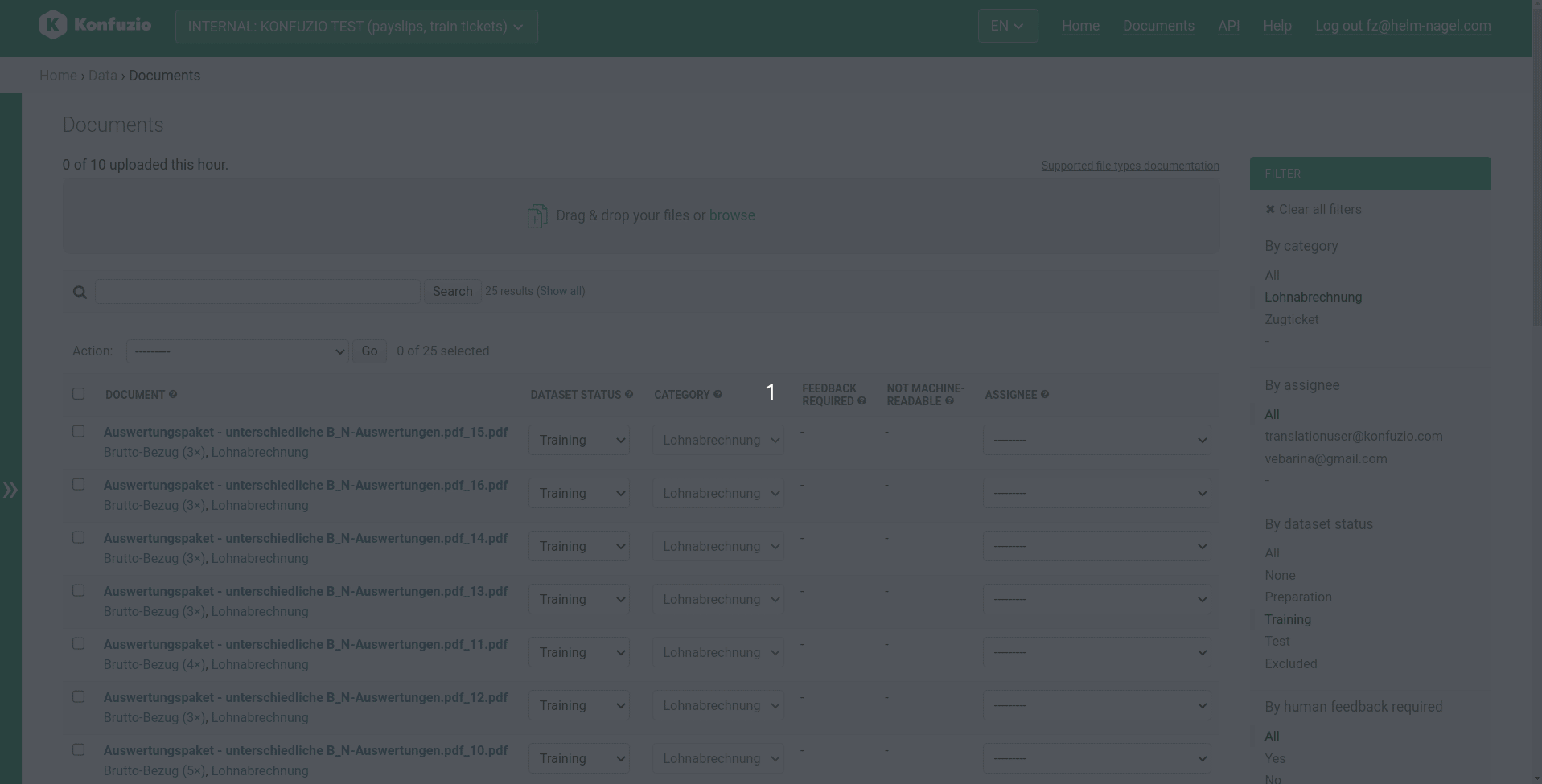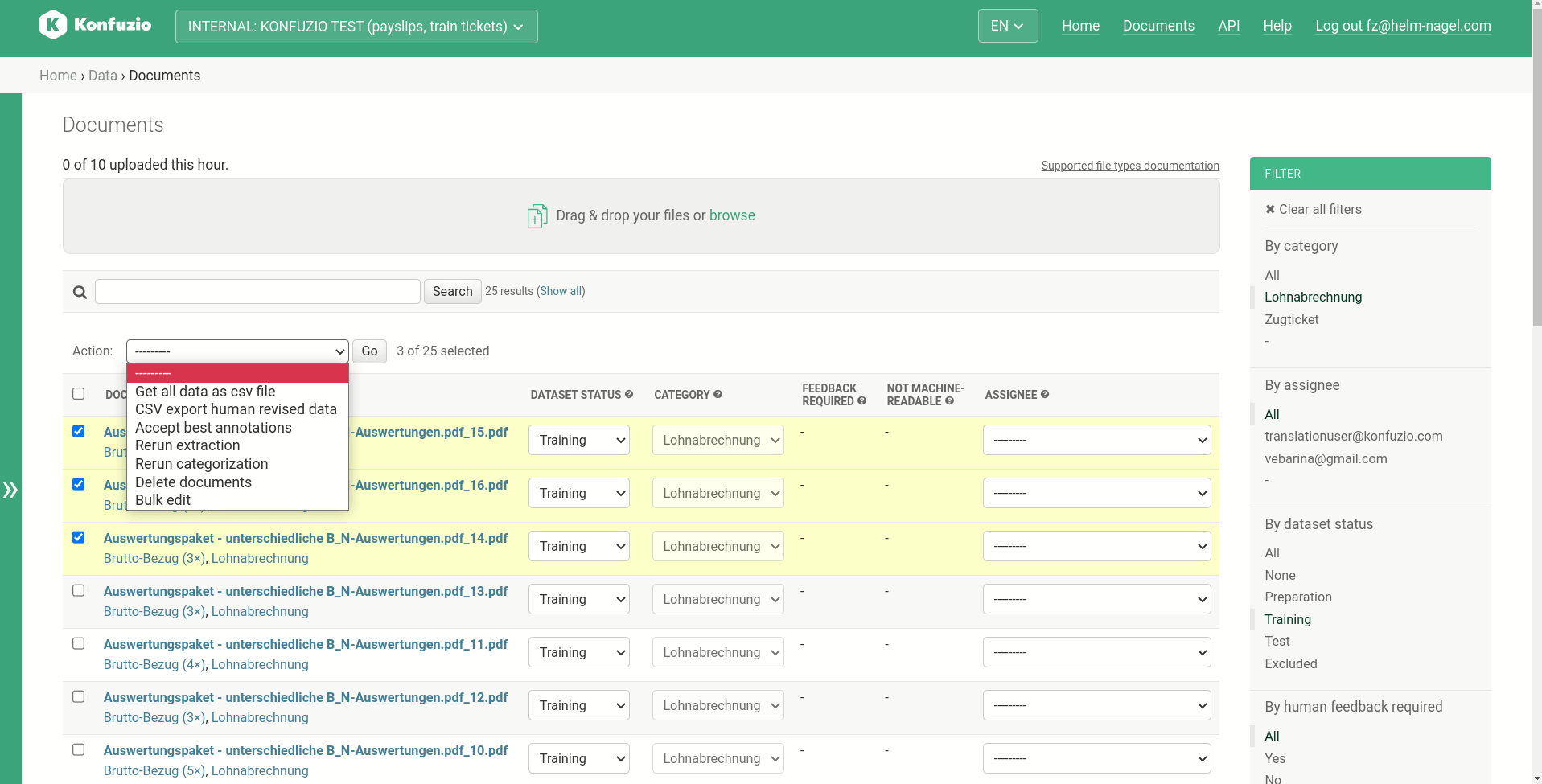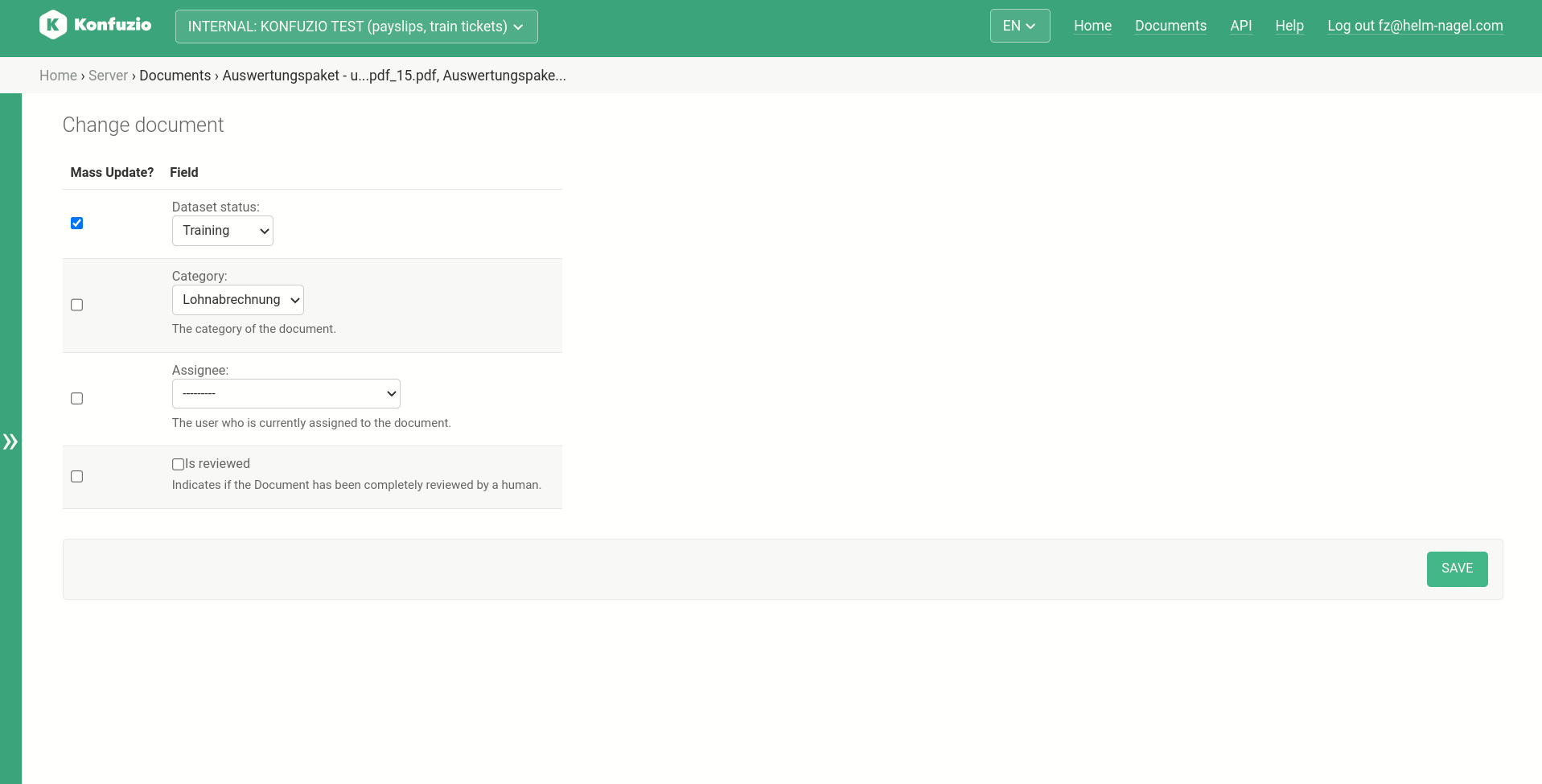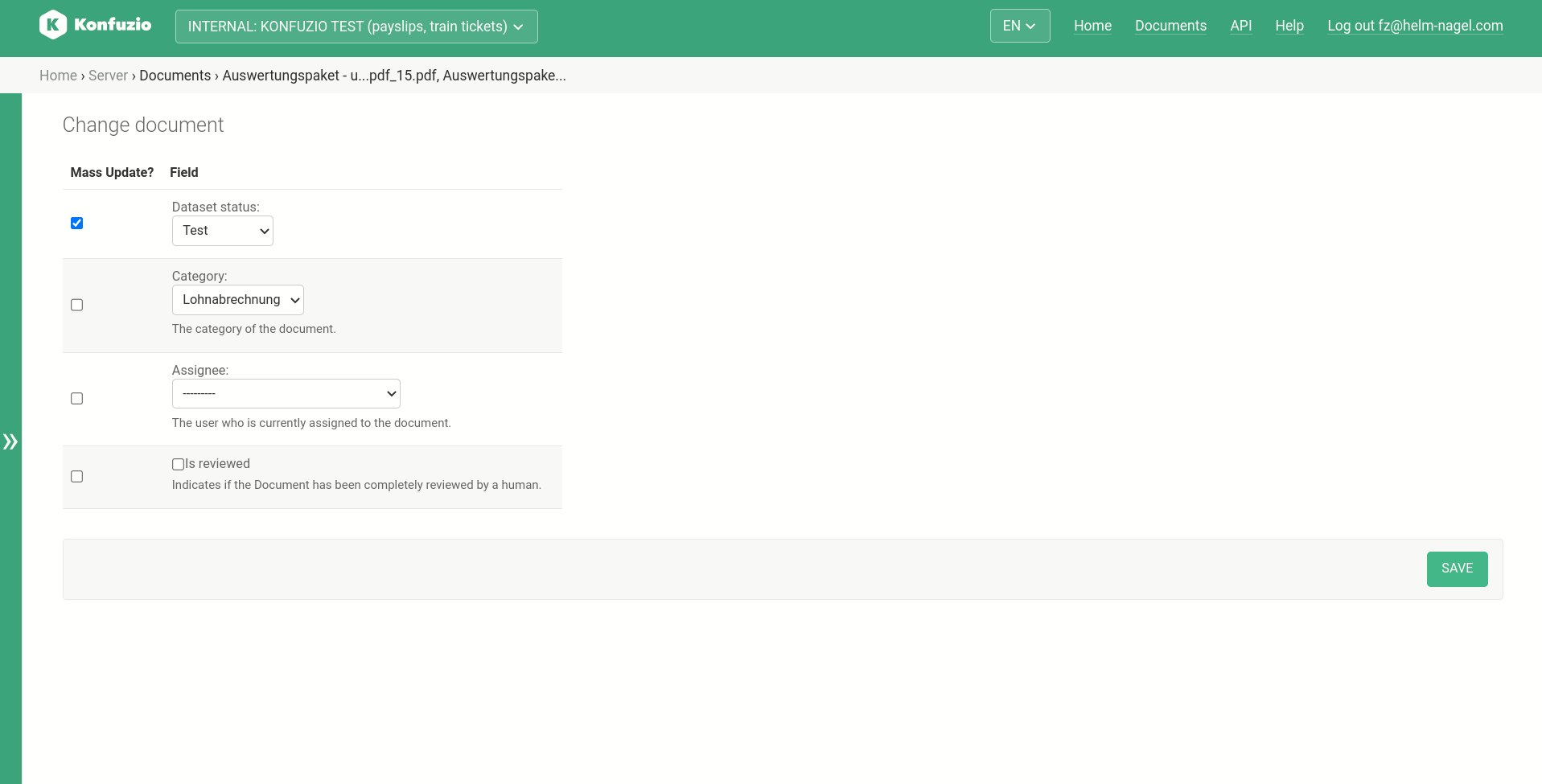
Bulk edit#
The bulk edit option allows to edit multiple Documents at once. Select the Documents, then choose “bulk edit”. Select the fields you want to edit and chose the desired value.
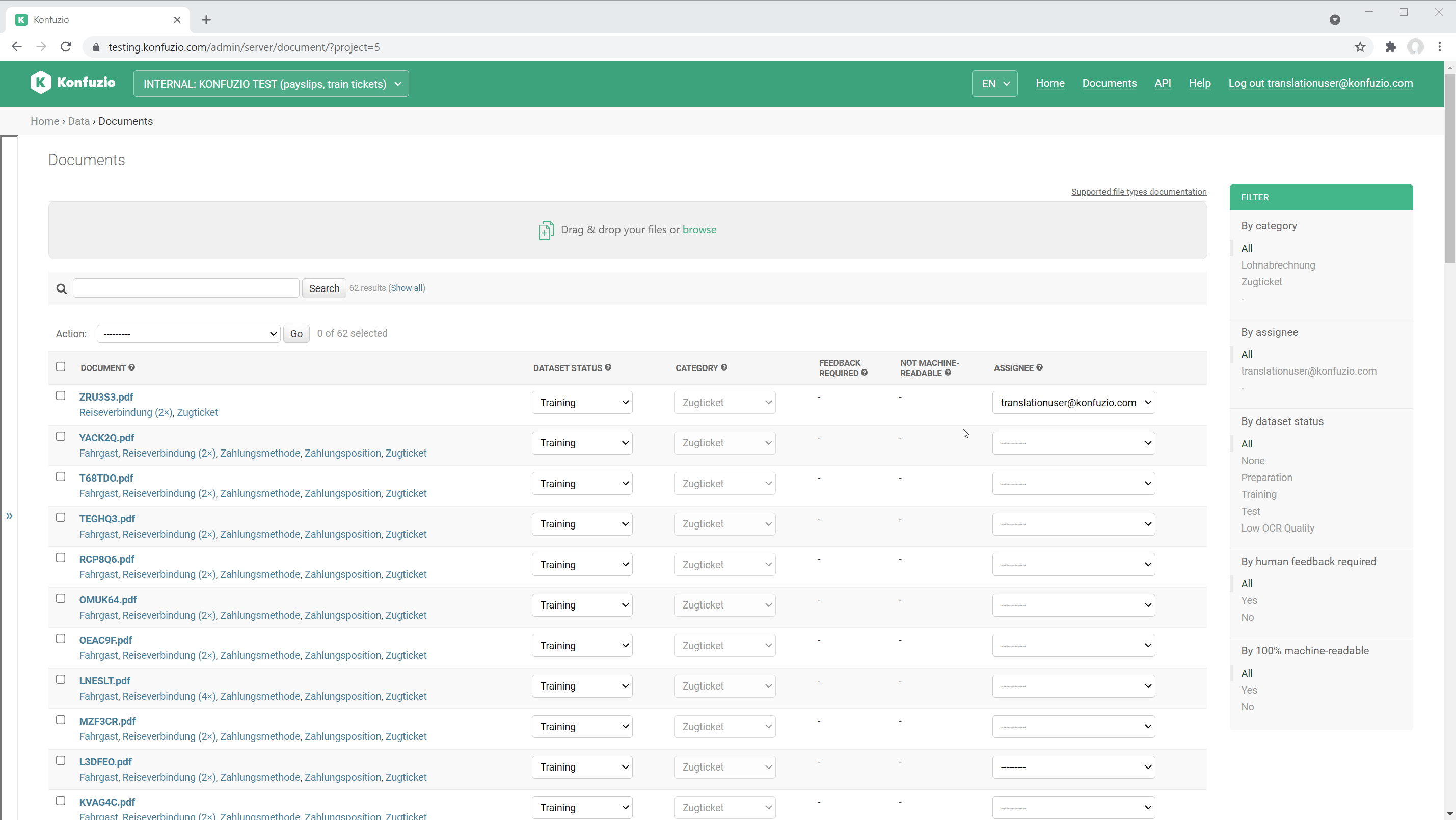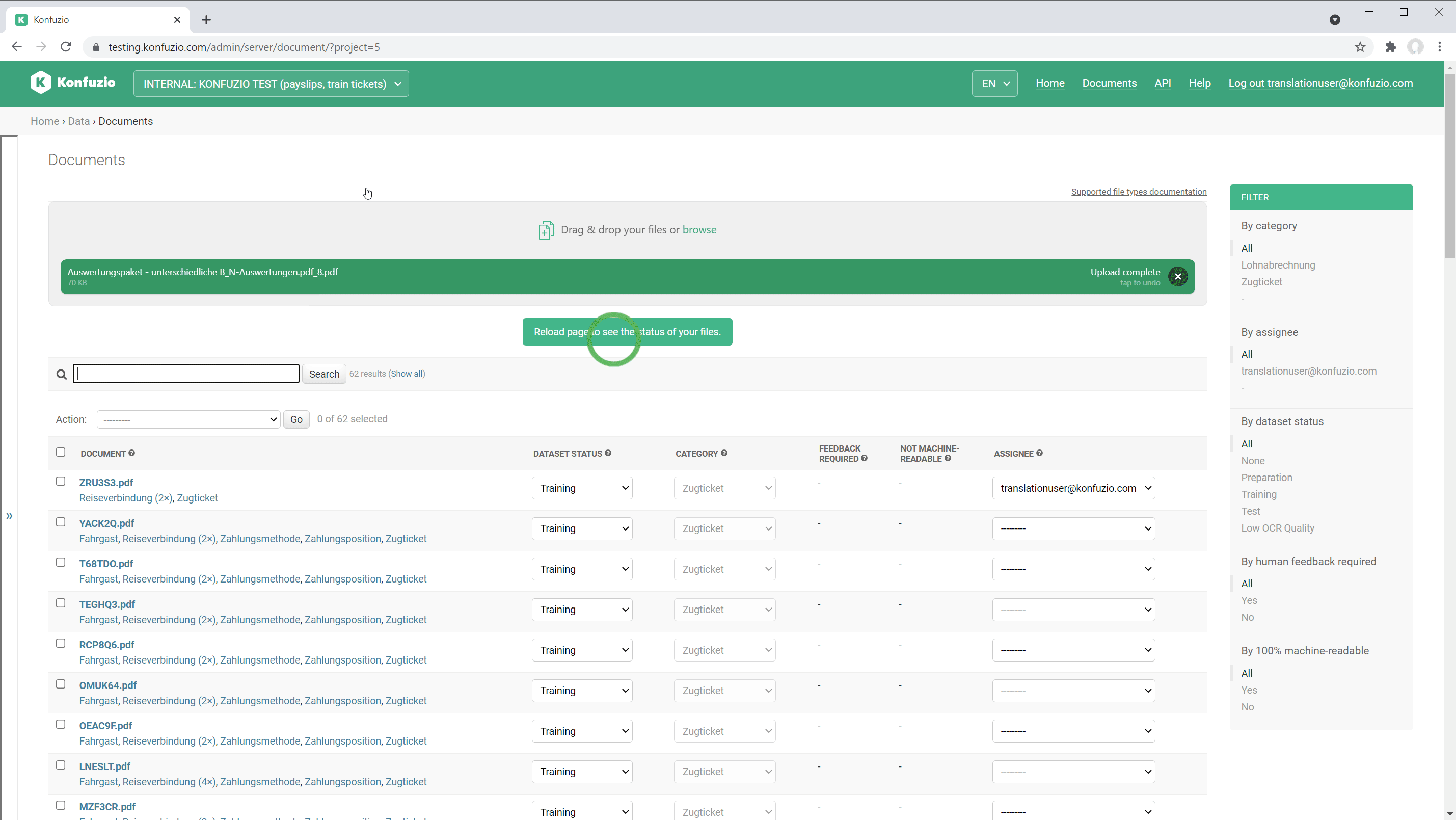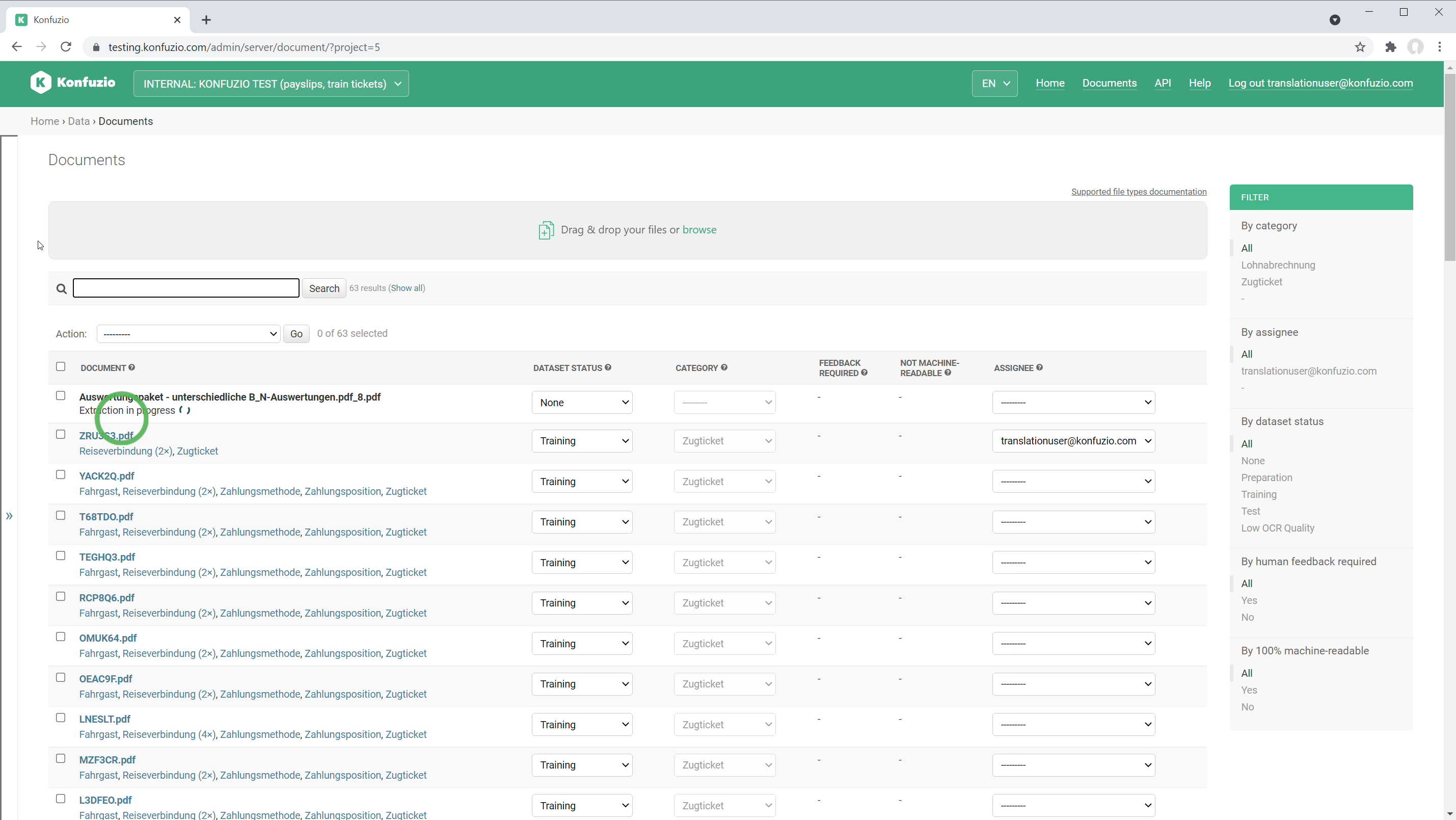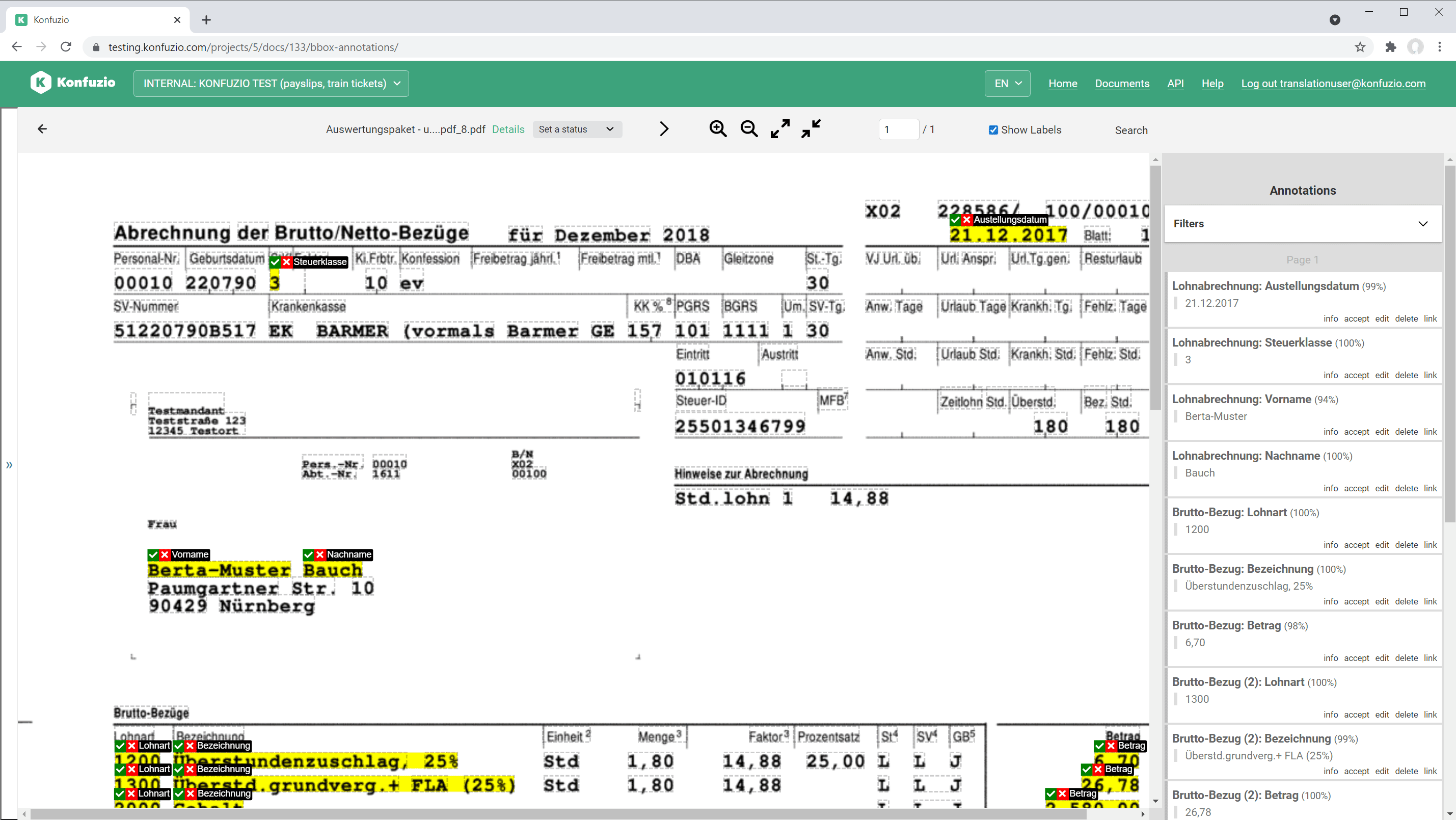
Document details#
Click on a Document and then click on details.
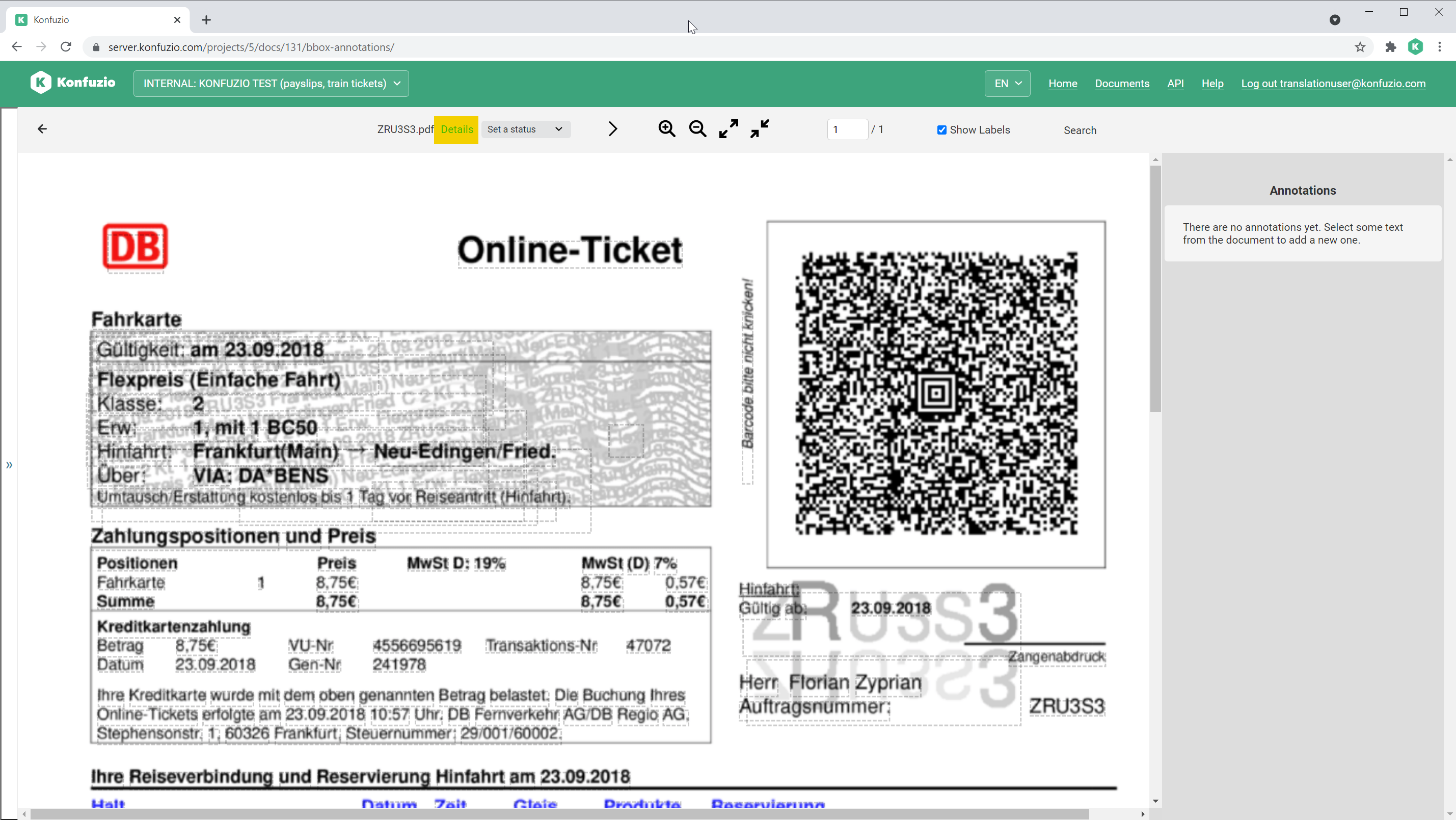
You have diverse options to change and inspect the Document:
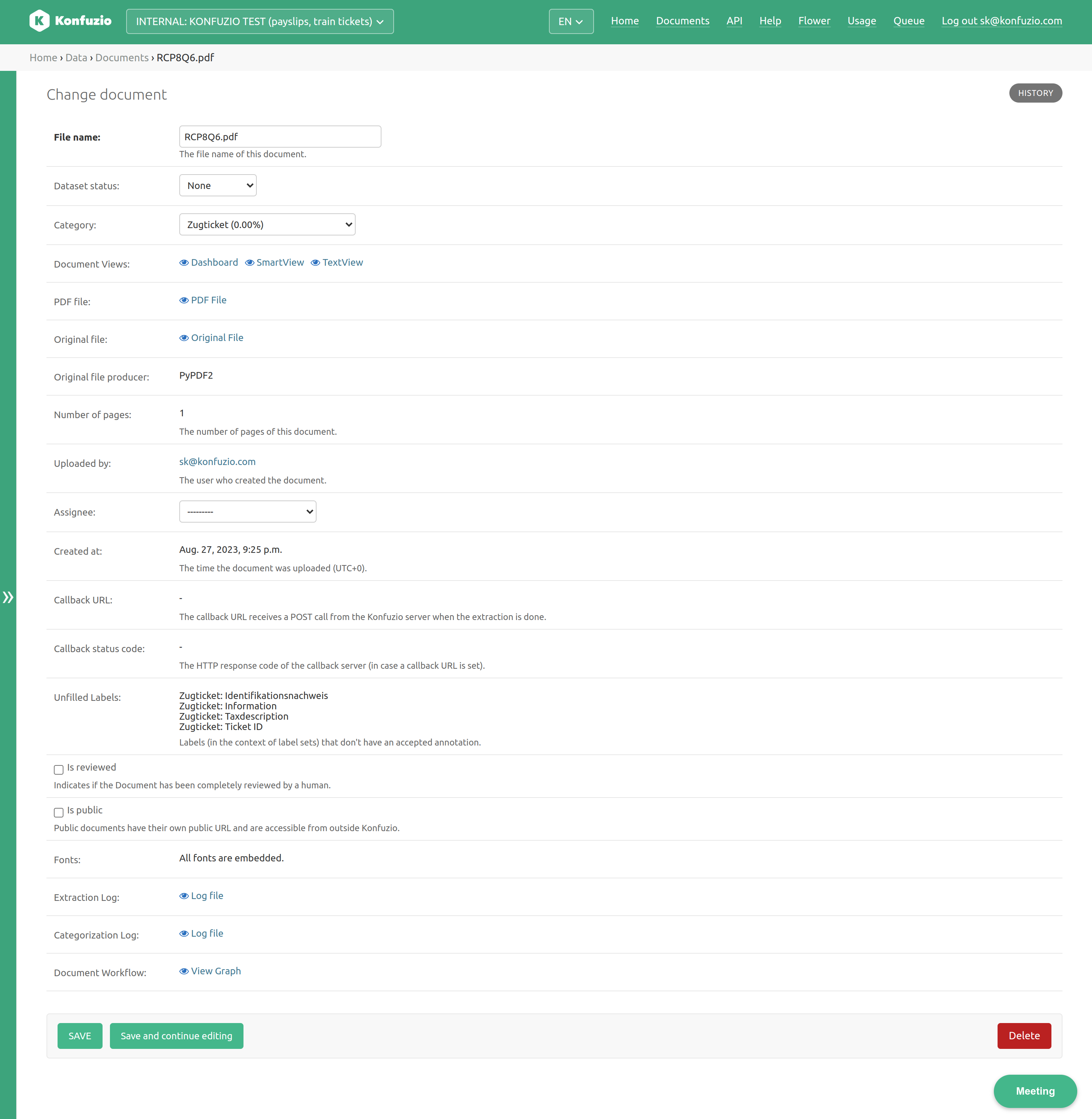
File name#
Name of the archivable PDF file.
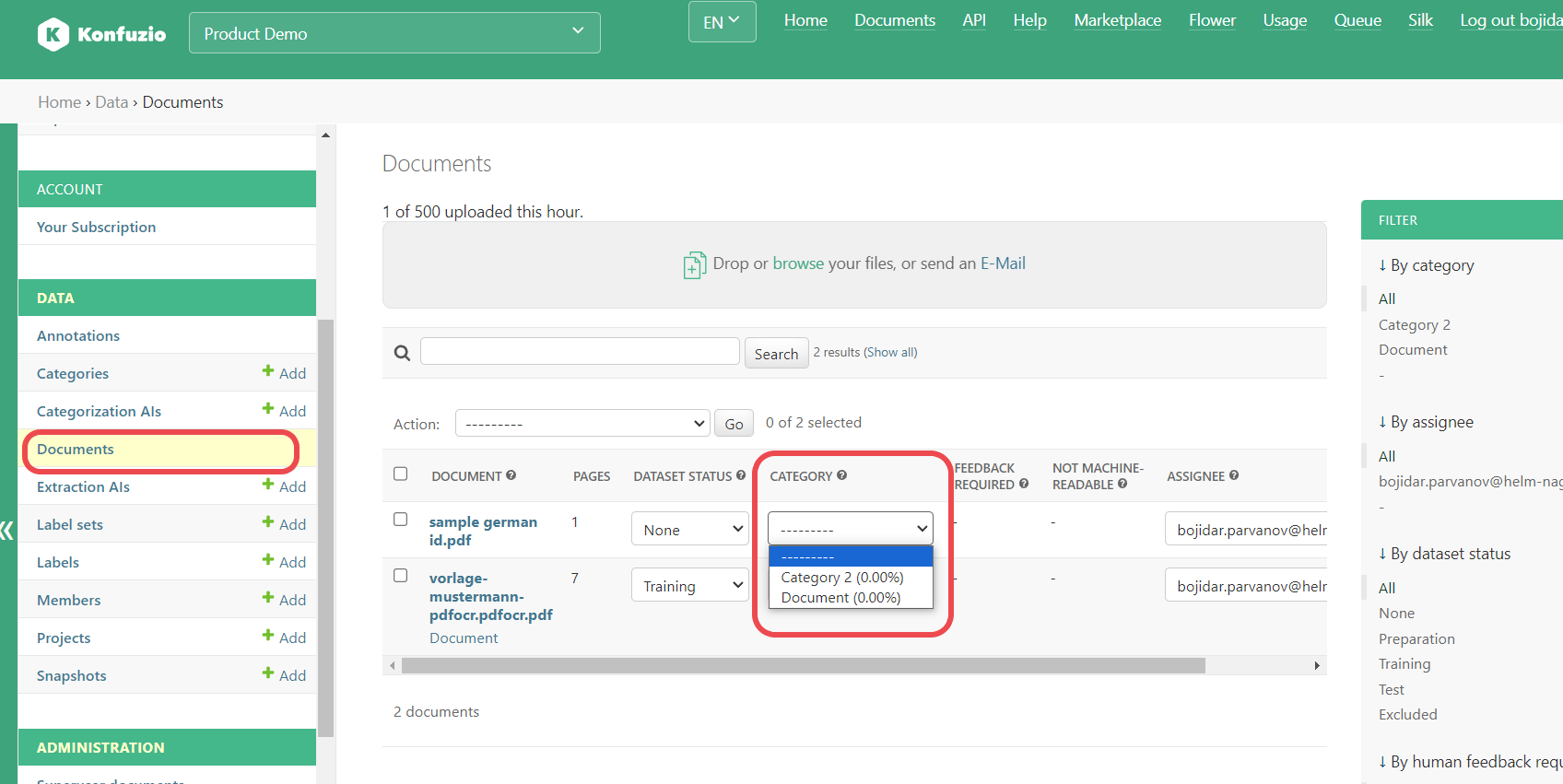
Dataset status#
The status of a Document in a dataset, for example, Preparation or Training. Full list can be found here.
Change the Dataset status by clicking on the dropdown and selecting the desired new Dataset status.
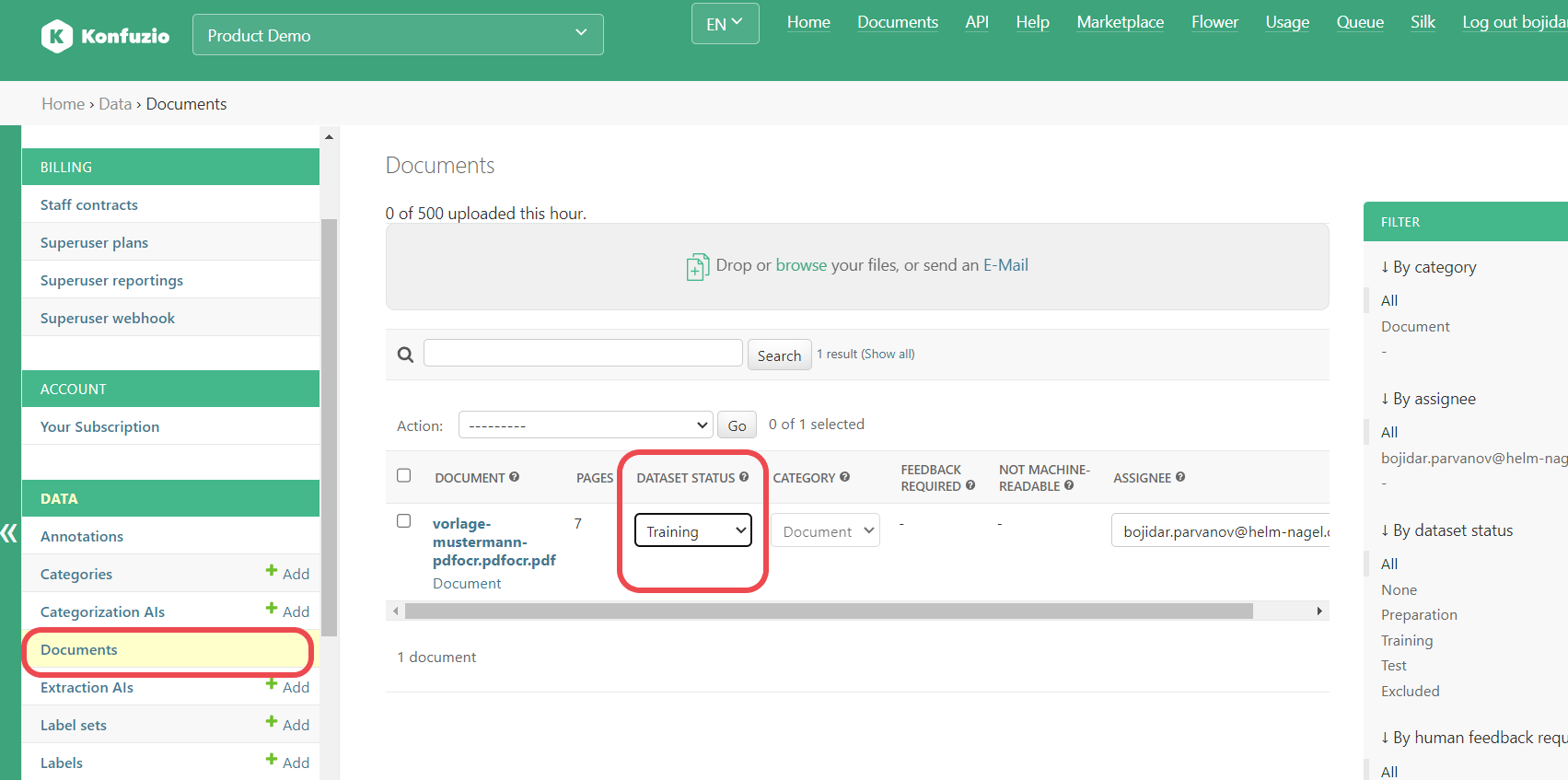
Assignee#
User assigned to work on this Document.
Category#
See Categories
You can manually change the Category by clicking on the dropdown and selecting the desired new Category. If there is an active Categorization AI, the Category is assigned automatically after uploading the Document.
Links#
See Document views
PDF file#
Link to an archivable PDF file, which is generated based on the OCR results.
Original file#
Link to the file representing a Document. This file, originally uploaded, has potentially undergone some modifications. For encrypted PDFs, attempts are made to remove encryption to facilitate further processing. If File Splitting is utilized, only the Pages included in the split form the original file. If the file is corrupted, efforts are made to repair it. See Supported file types.
Original file producer#
Software used to create the original file.
Number of Pages#
Number of Pages of the original file.
Uploaded by#
User who uploaded the Document.
Created at#
The time the Document was created.
Callback URL#
Webhook in case REST API is used. Incoming requests from the IP ranges of our Provider need to be accepted. Please refer to “EIP-pool” IP ranges here
Callback status code#
Status of the receiving service after webhook was triggered.
Unfilled Labels#
Labels (in the context of Label Sets) that don’t have an accepted Annotation.
Is reviewed#
Indicates if the Document has been completely reviewed by a human.
Is public#
Public Documents have their own public URL and are accessible from outside Konfuzio (e.g. via Konfuzio DVUI). Public Documents will be excluded from the Document list.
Fonts#
In case the Document is a PDF file, this displays if all fonts are embedded in the PDF. If all fonts are embedded, your Document may not be displayed correctly.

Extraction logs#
The log of the Extraction AI run. The log contains useful information for debugging purposes. If you have uploaded a custom model, any log messages created in the extract method will be displayed here.

For example, for the custom Paragraph Extraction AI, the following log might be displayed:
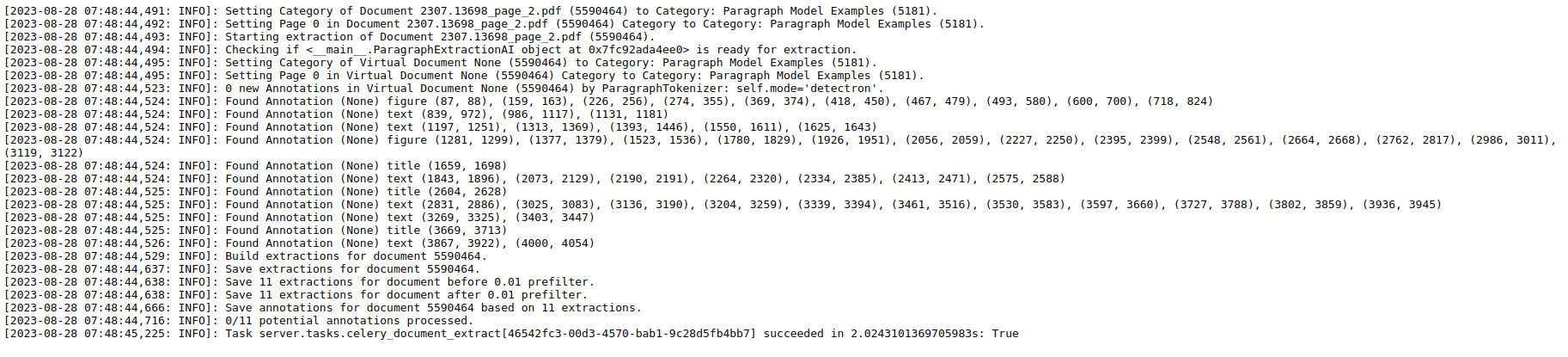
Categorization logs#
The log of the Categorization AI Run.

Document workflow#
This illustrates the workflow of the Document. The shown workflow is generated based on the current settings of the Project. It might differ from the workflow that had actually happened. A workflow consists of multiple background processes. The workflow graph helps to gain an understanding for the processing time of a Document and to finetune self-hosted Konfuzio Server installations.

Dataset status#
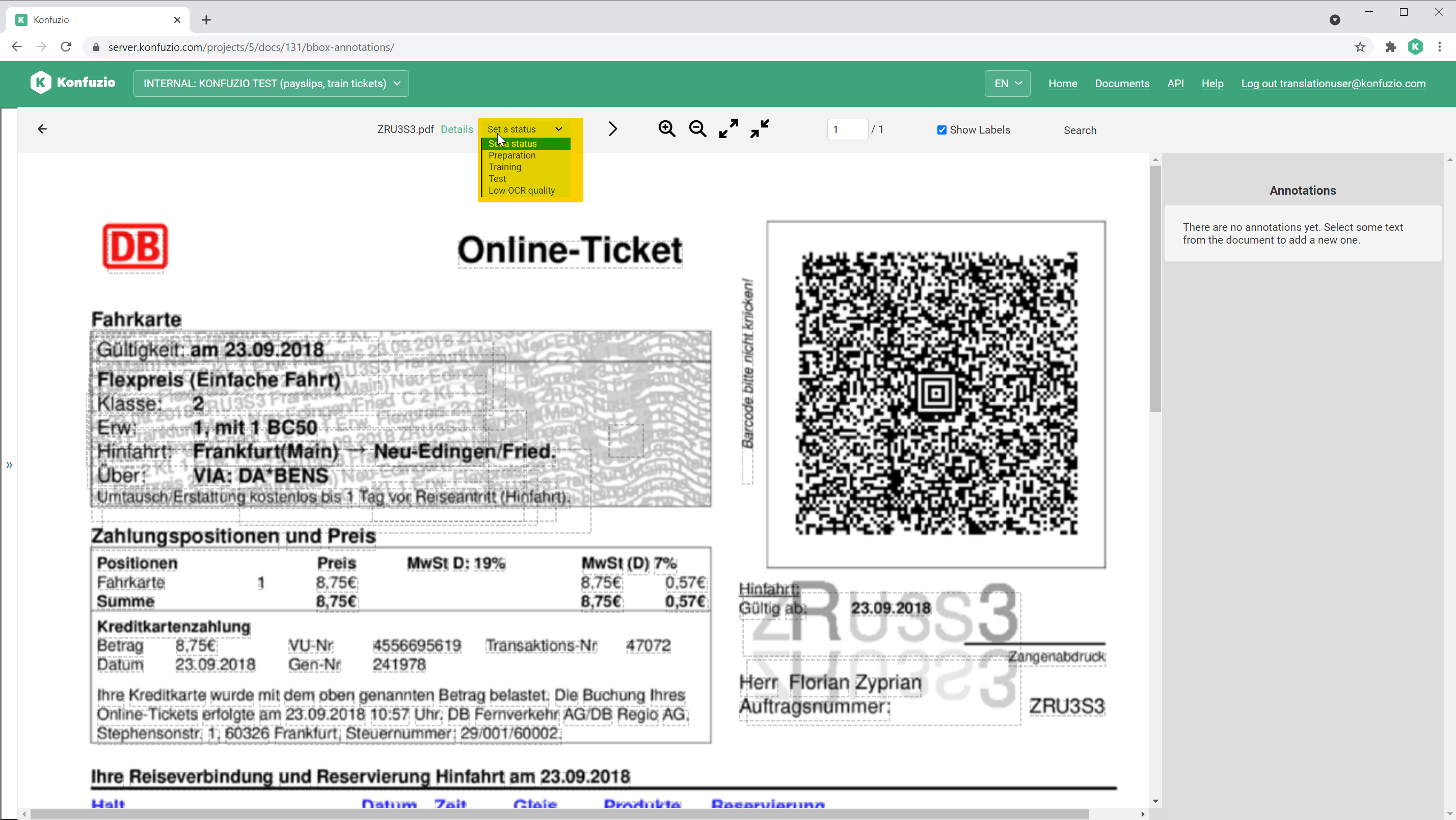
Status: Set a status (None)#
The default status of a Document.
Status: Preparation#
Add any Document you want to add to the test and training set before you start labeling it. This step is crucial to check if the Document you want to add is already in the training or test data.
Status: Training documents#
The training Documents provide the data to train Extraction AIs of a Category.
Status: Test documents#
The test Documents provide the data to evaluate Extraction AIs of a Category.
Status: Excluded#
If you find out that a preparation Document should not be used for testing or training due to its quality, exclude the Document.
Document views#
A Document Viewer is the user interface for manually annotating the Document, reviewing AI-generated extractions and genrally investigating the Document. There are thre different Document Viewers that can be used.
SmartView#
The SmartView is the default Document view.
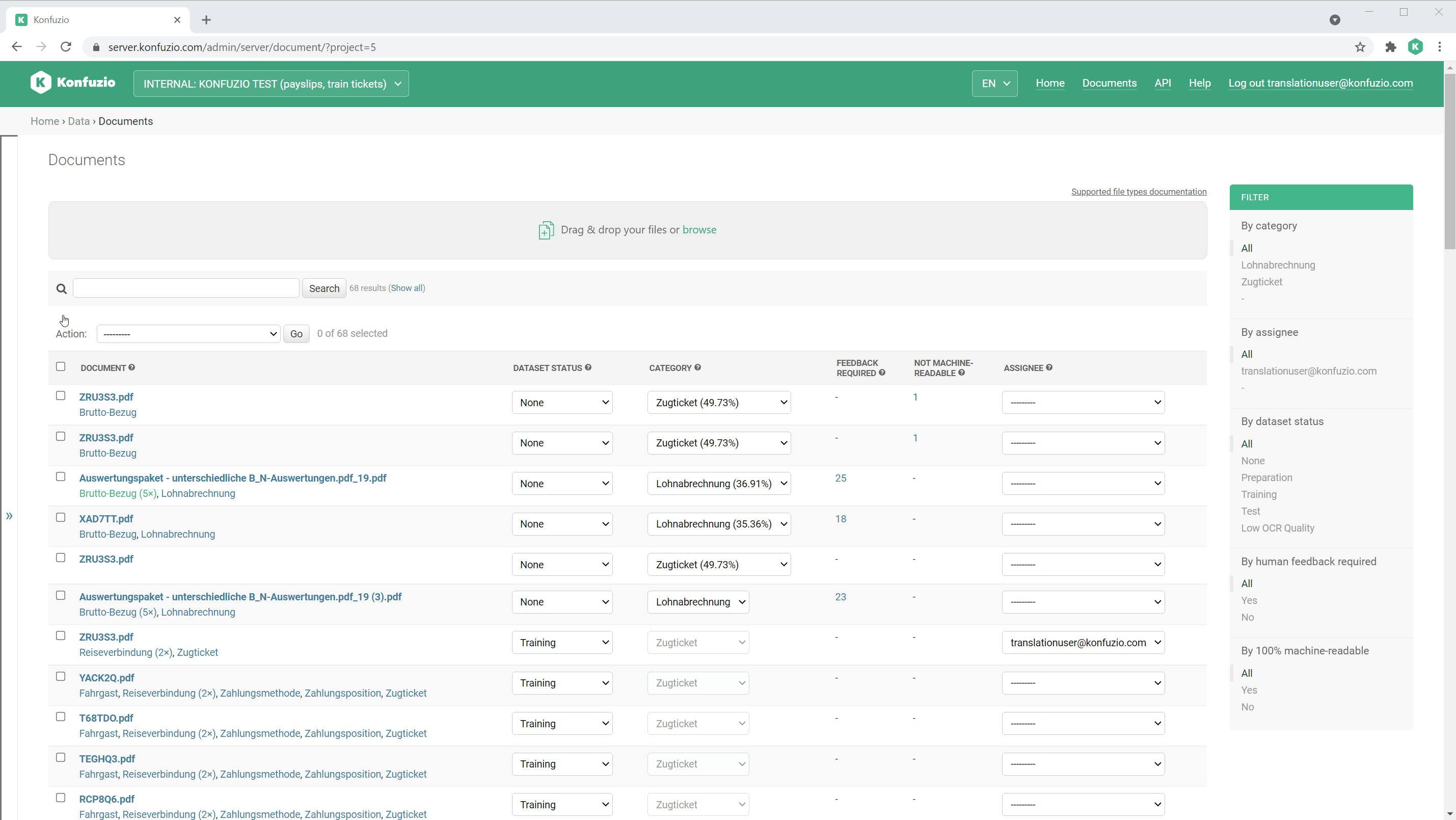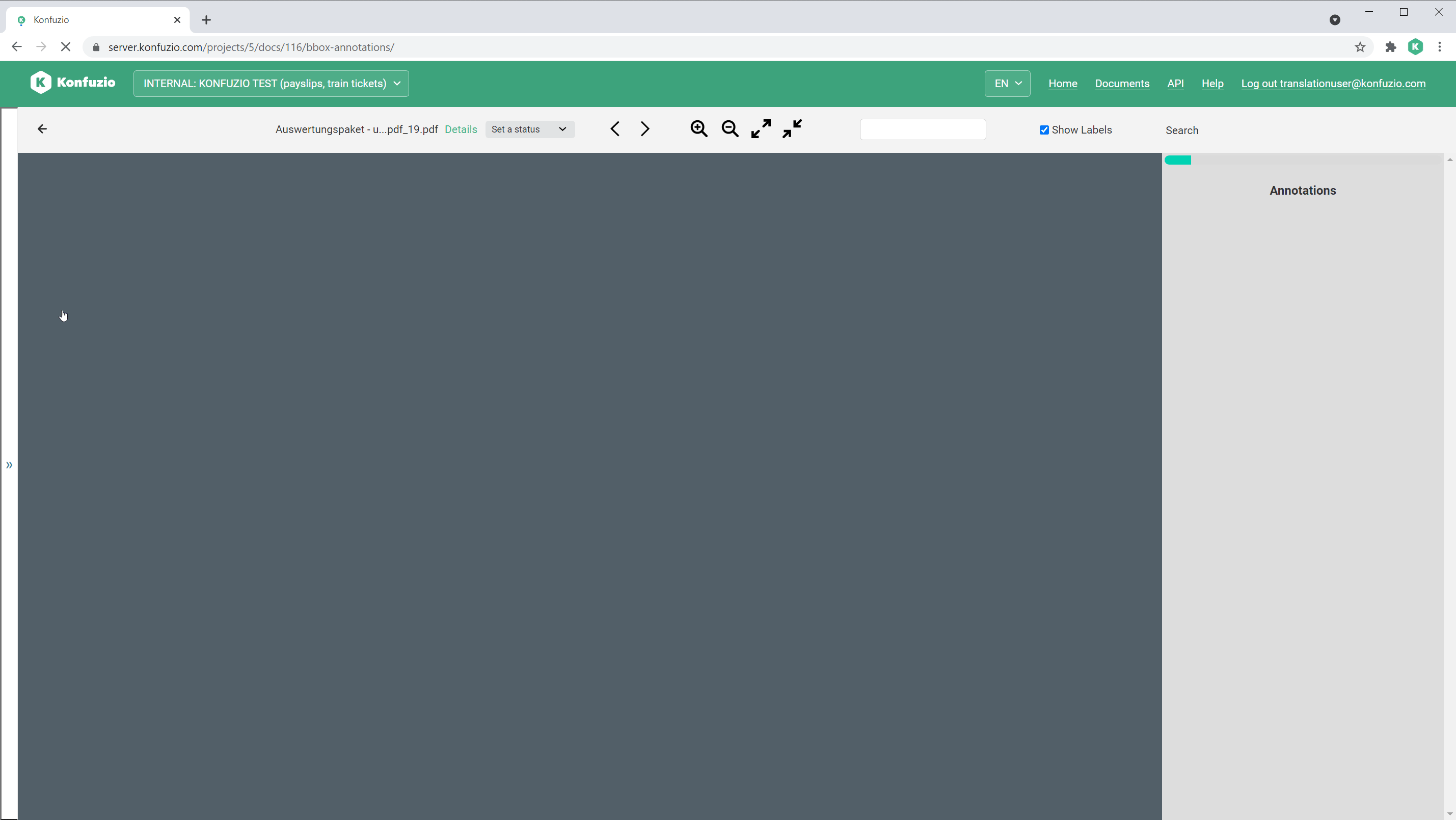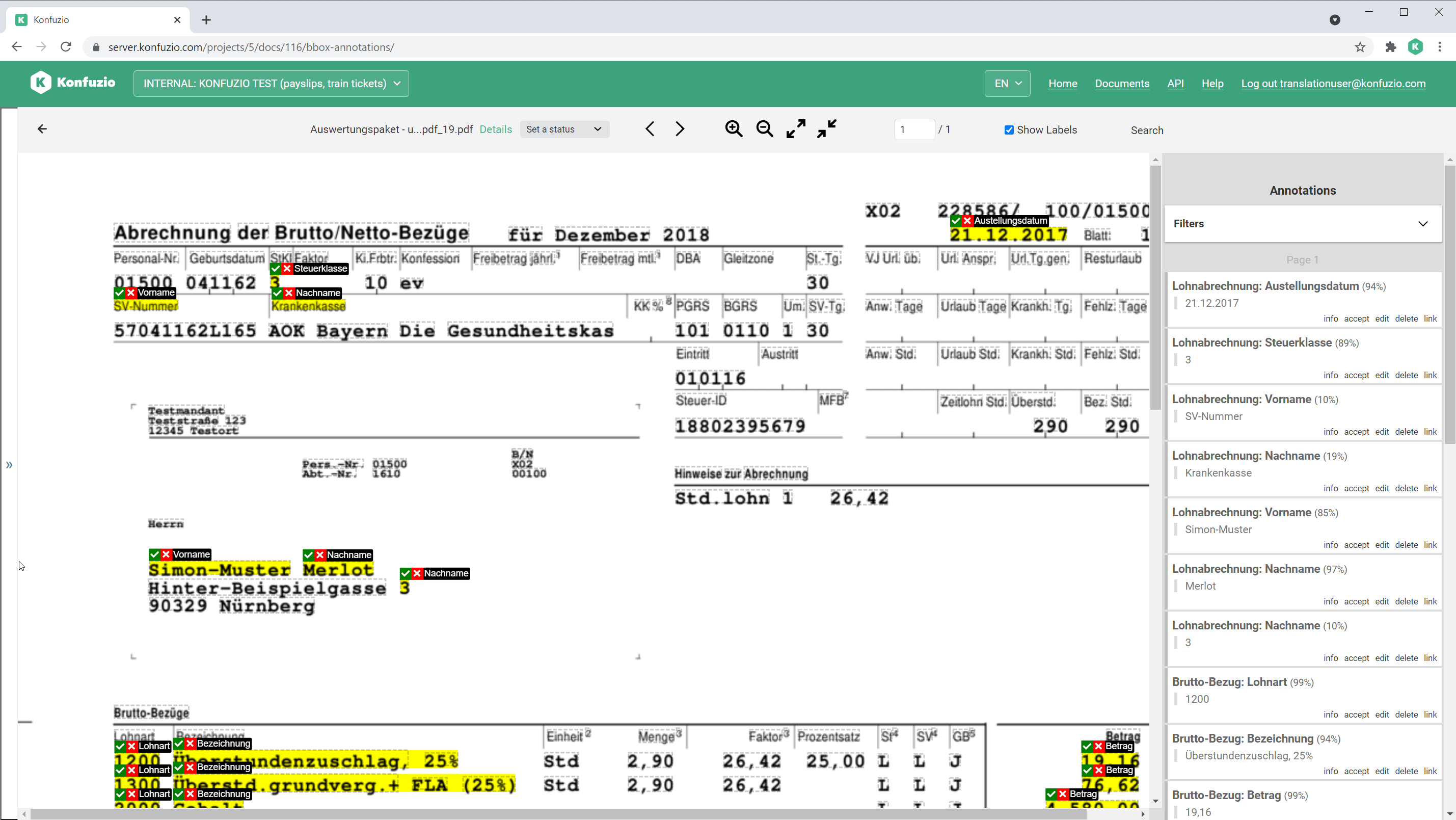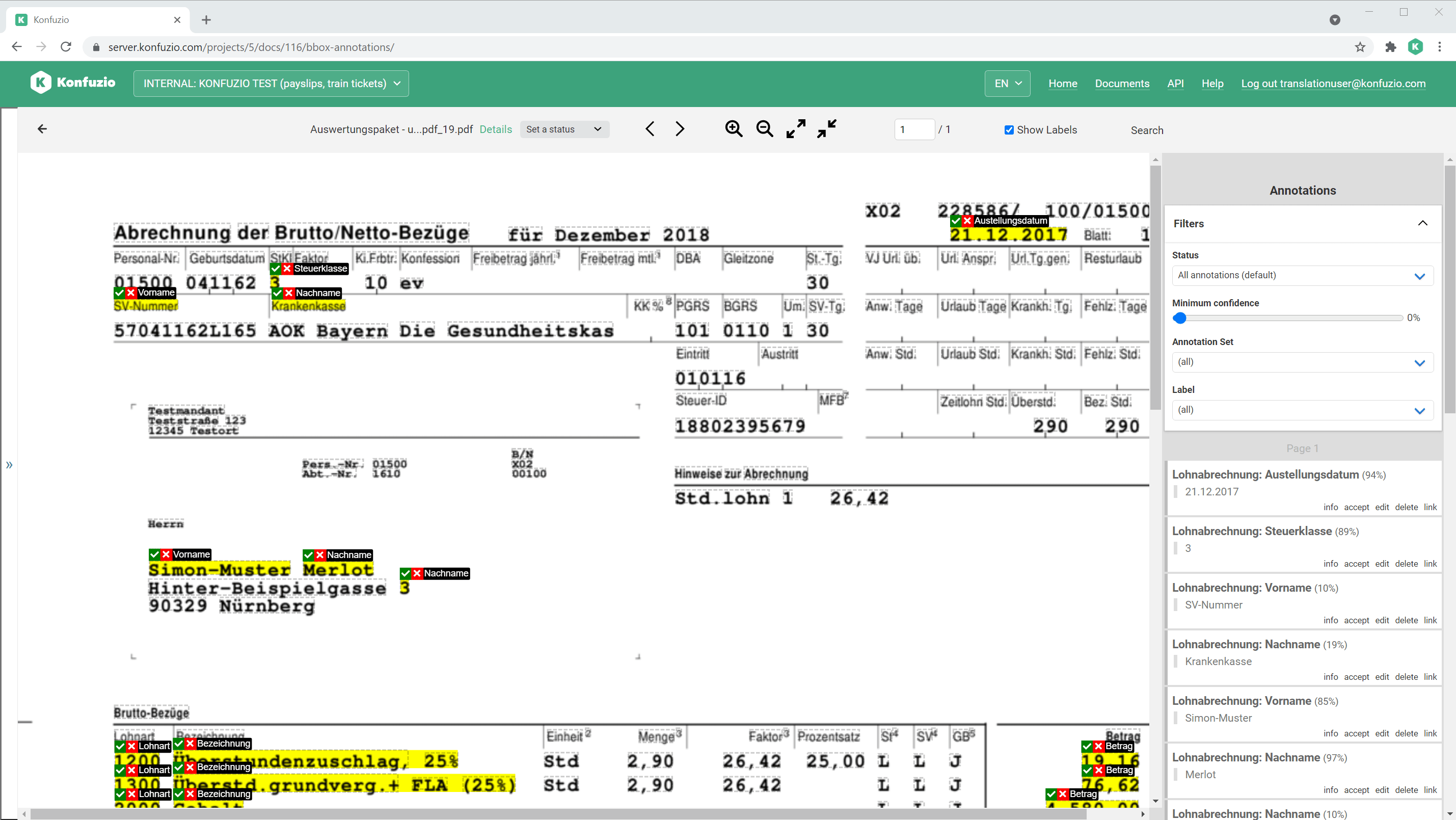
Have a look at Annotations to find out more.
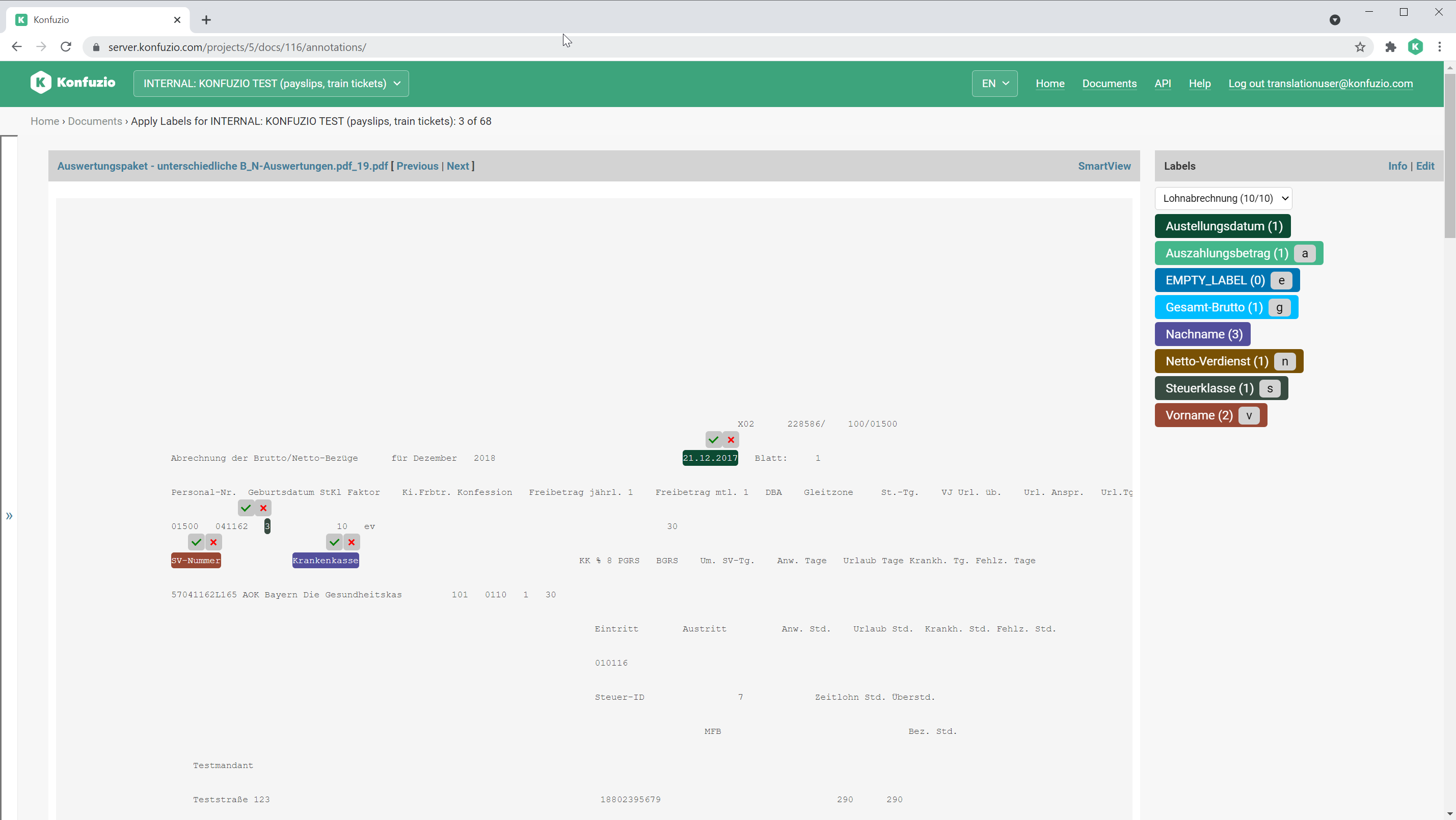
TextView#
The TextView allows you to edit Annotations via raw text.
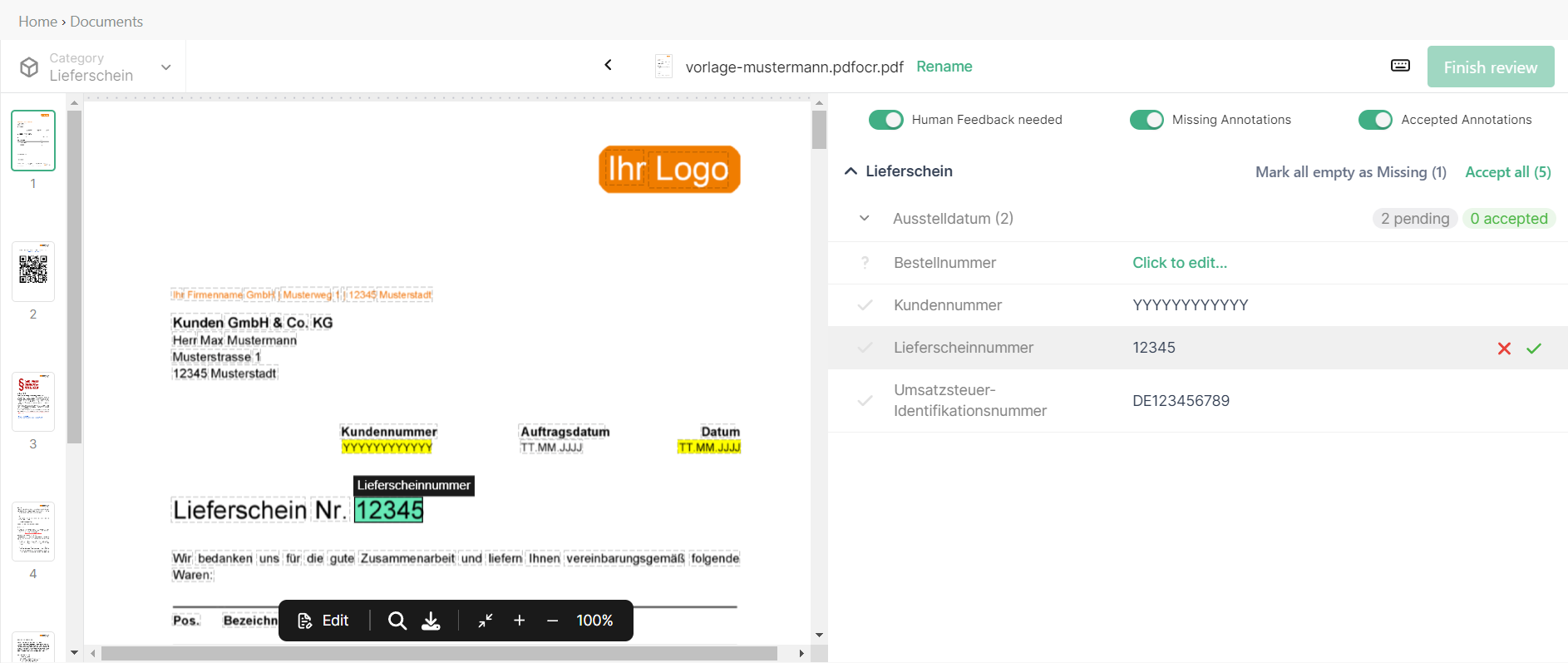
Document Validation UI (also referred to as Dashboard)#
This is the latest Document Viewer, which has been highly optimized for usability. Here you can find more about this Document Viewer.
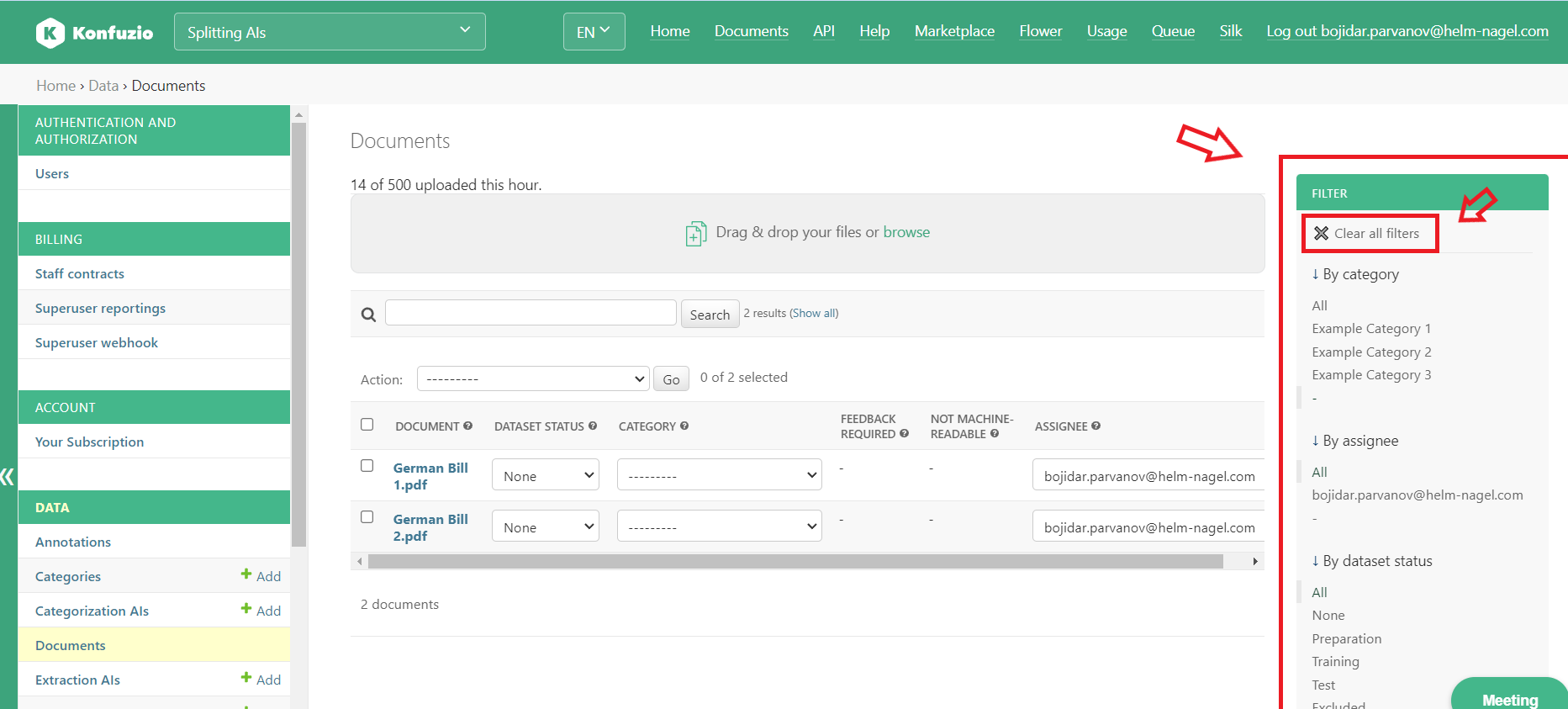
Filters#
The number of Documents within a Project can grow rapidly. Therefore, in order to enable you to find the Documents that you are looking for as quickly as possible, we have introduced multiple filters.
All filters can be found in the Document list view - where you see all Documents for the Project. You can combine multiple filters together or remove all filters by using the ‘Clear all filters’ button at the top of the filters section.
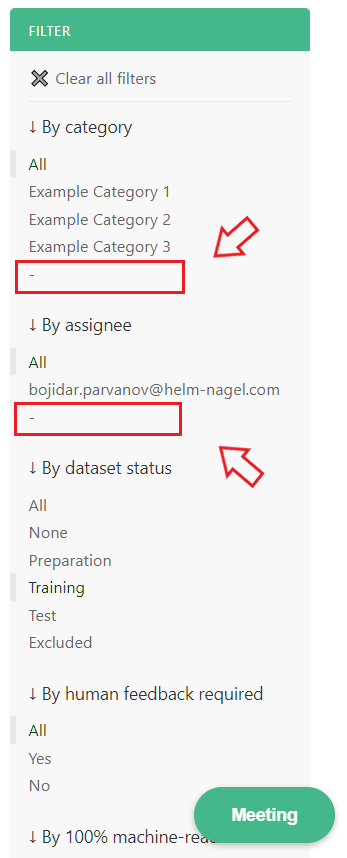
Within some filters, there is a ‘dash’(-) value. Choosing this value will show you all Documents that do not have any value for that specific filter. For example, choosing the ‘dash’ option for the ‘By assignee’ filter, will show you only Documents that are not assigned to anyone.
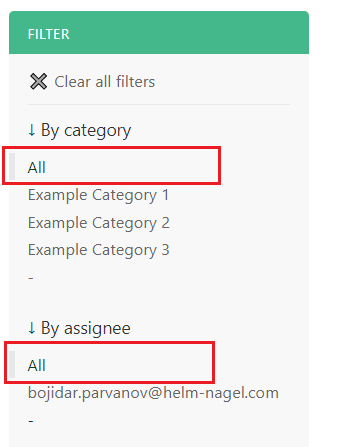
Within most filters, there is an ‘All’ value. Choosing this value will dismiss this filter. This means that the Documents will not be filtered at all based on this filter - Documents with any or no value for this filter will be shown. For example, choosing the ‘All’ value for the ‘By category’ filter, will show you Documents from all Categories and Documents that do not belong to any Category.
Basic filters#
Below you can read about the basic filters and how to use them.
By assignee#
Using this filter you can find Documents assigned to a particular member of the Project or assigned to no member at all (using the ‘dash’ value - see above).
Reference: see the Assignee section.
By Category#
Using this filter you can find Documents that belong to a specific Category or do not belong to any Category at all (using the ‘dash’ value - see above).
Reference: see the Category section.
By dataset status#
Using this filter you can find Documents that belong to a certain dataset.
Reference: see the Dataset status section.
By Human feedback required#
This is a binary filter. The ‘Yes’ value shows you either Documents with AI-extracted Annotations that need human feedback, so that these Annotations can be used for further model training upon providing the human feedback. The ‘No’ value shows you Documents that do not contain any such Annotations, which might be because no AI model has been run on these Documents, no Annotations were found by the AI model or a human has already provided feedback to the respective AI-extracted Annotations.
Reference: see the Automated Annotations section.
By 100% machine-readable#
This is a binary filter. The ‘Yes’ value shows you Documents that have only machine-readable Annotations. Whereas the ‘No’ value shows you Documents that have at least one Annotation that is not machine-readable. Machine-readable refers to the possibility of converting the content of the Annotation to the data type specified in the Label for that given Annotation.
Reference: see data types for Labels.
Advanced filters#
Below you can read about the advanced filters and how to use them.
By Extraction AI:#
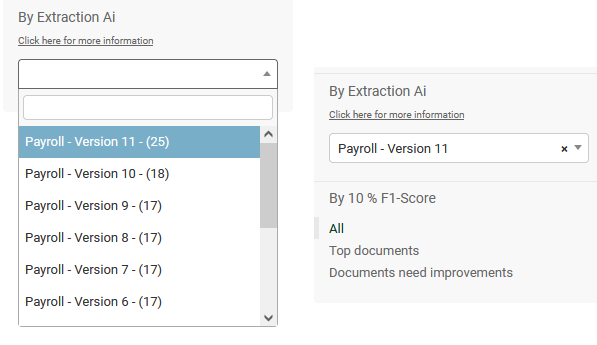
If Documents in your Project have been evaluated by an Extraction AI, this filter can be selected. The dropdown of the filter will give you a list of the AIs and versions the Documents have been evaluated by. The number within the brackets in the filter corresponds to the amount of available Documents by this Extraction AI.
Once the initial AI filter has been selected, a secondary filter will be visible which is called “By 10 % F1-Score”.#
This filter offers two options, firstly “Top Documents”, with which you can see the top Documents for the selected AI. And secondly the “Documents need improvements” option, which lets you select the worst performing Documents by “ F1-score” for the selected AI. The filtering is only available for current evaluations, meaning that as soon you alter annotations on the Document, it will no longer be available in the AI or in the “By 10% F1-Score” filter. At this point, a new AI evaluation for the Category would have to be made.
Rounding:
Please note that the results in this filter are rounded up. If there are less than 10 Documents in the AI’s evaluation, then we return the top-1 and worst-1 document. Between 10 and 100 results, we round up to the nearest decimal, meaning that if there are 16/26/36/… Documents in the AI’s evaluation, we return 2/3/4/… results for the F1-score filter. “True” 10% results are only returned for AI’s which have more than 100 Documents available in the AI’s evaluation.