Projects#
A Project is the main concept in Konfuzio. No data can be shared across Projects, only AI models can be shared.
Create a Project#
Go to Home and click on the Add button next to Project to create and name a new Project.
Project details#
Name#
Verbose name of the Project.
Document Viewer#
This setting allows you to change the Document Viewer. A Document Viewer is the user interface for viewing and inspecting all Documents and their Labels within the project.
Here you can find more about the available Document Viewers.
Decimal separator#
Change the decimal separator used to compile the CSV File. Have a look here to see how to change the decimal separator in MS Excel.
Enable assignee#
Allows assigning users to Documents if enabled.
Notify assignee#
If Project’s Document has value for assignee field and Project’s notify_assignee value is True,
then we send emails about processing of this Document to assignee person.
Default assignee#
We allow defining a “default assignee” user on Project level for the Project’s Documents. If this value is declared on a
Project, newly uploaded Documents are automatically assigned to the Project’s default assignee. It’s possible to set this
value from both the API and the Admin panel through the default_assignee field. When a Project is newly created, the
creation user is automatically set as default assignee (functionality in the Admin panel &
upwards v3 api only).
Wrong editing user warnings#
When enabled, this option will trigger a warning when the user editing the Document is not the assigned user. This can help you in your workflow by making sure that the right users are annotating their assigned Documents. No limitations or restrictions are imposed when this setting is enabled, the user can also simply reject this warning.
Automatically rotate Documents#
If enabled, when Konfuzio detects a file that is not oriented correctly, depending on the chosen option (“90 degree rounding” or “exact rotation”), it will rotate the relevant Page(s) automatically.
option “90 degree rounding”: Page(s) are automatically rotated to the nearest 90 degrees.
option “exact rotation”: Pages(s) are automatically rotated at the exact rotation angle in order to make sure that text is displayed horizontally.
Example of “exact rotation”:
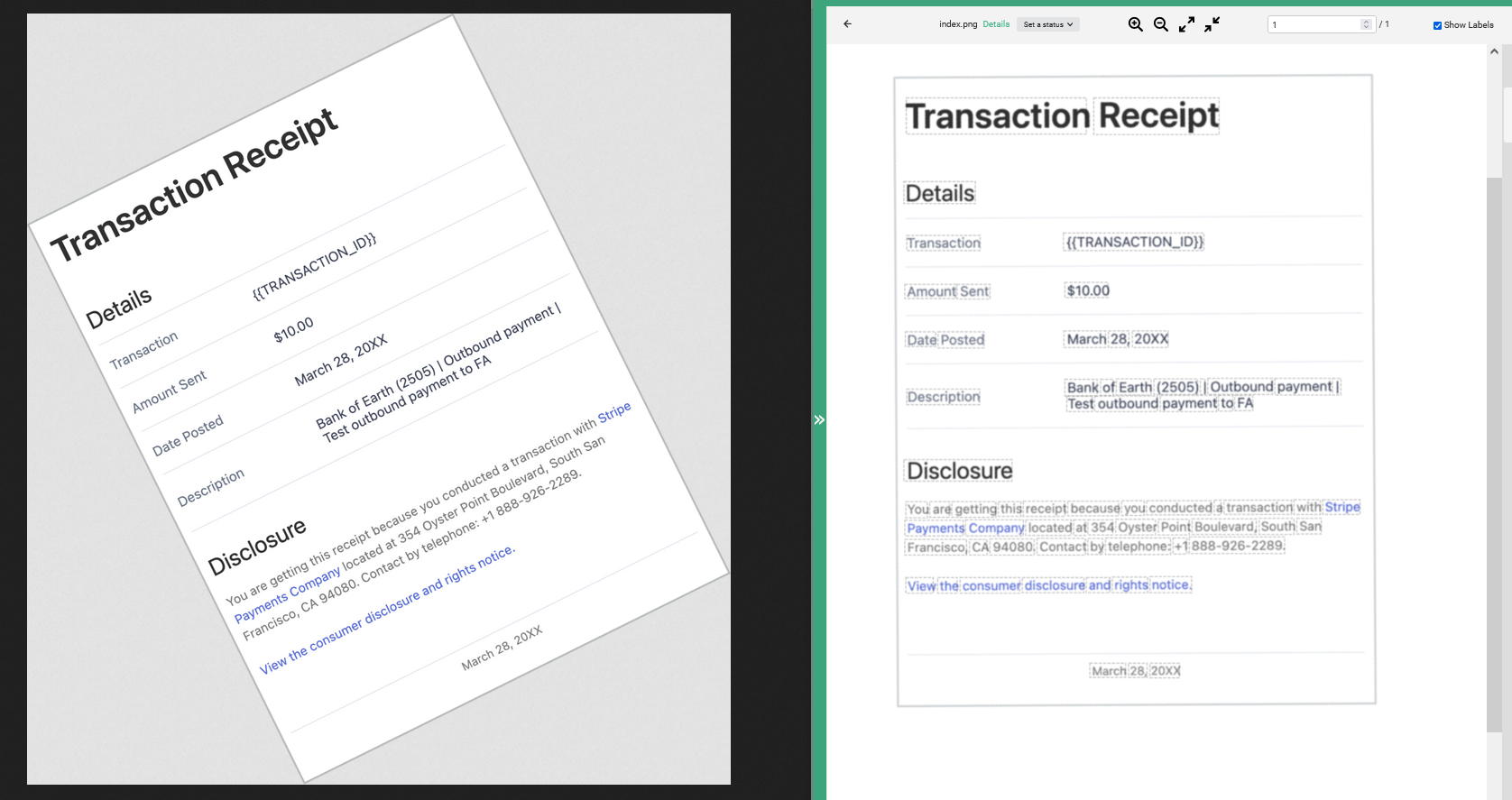
Left: A Document before being uploaded, the Document is angled.
Right: The Document after being uploaded, with automatic rotation enabled and option “exact rotation”.
This feature does not change existing Documents, it only applies to newly uploaded ones.
For new Projects, the option to rotate at “90 degree rounding” is selected by default.
This feature is not available on all Projects.
Categorization AI#
As soon as you have trained a Categorization AI, you will be able to:
Activate the latest trained version or
Deactivate it by opting not to select any version (i.e, choosing
---------)
from the Categorization AI dropdown menu, conveniently located within the Project’s Settings.

Categorization AI parameters#
There are advanced configurations for the training of a Categorization AI that can be adjusted to achieve a better fitting for your case.
The Categorization AI, by default, is based on a NBOW model, which stands for Neural Bag-of-Words.
This model is a simple and efficient way to represent text for document categorization. It takes the text of the Document as input and transforms it into a mathematical representation that the machine can understand. It, later, uses that to predict the category of the Document.
Therefore, the categorization of a Document will be based on the text of the Document’s Pages.
This model is still able to achieve comparable performance to some state-of-the-art AIs whilst being considerably faster.
However, Konfuzio offers the possibility to change the default configuration of the Categorization AI under the Categorization AI parameters section.

You can opt for a more complex model, such as BERT or ELECTRA, which are based on the advanced AI Transformer architecture and are able to capture more complex patterns in the text. This can be done by passing the following JSON object in the setting the Categorization AI parameters where text_model_name is set to bert-base-cased for example.:
{
"document_classifier_config": {
"text_model_name": "bert-base-cased"
}
}
N.B: You can find a full list of the supported values for text_model_name here
Not only that, but you can also combine the text features with image features, which can be useful when the text of the Document is not enough to predict its category.
To do that, you need to pass an image_model_name as well as a text_model_name in the document_classifier_config object. For example:
{
"document_classifier_config": {
"text_model_name": "bert-base-cased",
"image_model_name": "efficientnet_b0"
}
}
N.B: You can find a full list of the supported values for image_model_name here
The usage of image features is disabled by default, however if you want to enhance the clarity of your JSON data structure you can add image_model_name to your parameters and simply write null in front of it:
{
"document_classifier_config": {
"text_model_name": "nbow",
"image_model_name": null
}
}
N.B:
If text_model_name is not present in the parameters, the default value of nbow is used.
If image_model_name is not present, the default value of null is used.
Furthermore, you have the option to customize the training parameters such as the number of epochs and batch size for the Categorization AI. This can be achieved by incorporating the document_training_config field within the Categorization AI parameters JSON and subsequently adjusting the n_epochs and batch_size attributes nested within it. The default values for n_epochs and batch_size are 20 and 1 respectively. However, it is recommended to run multiple experiments with different values to find the optimal configuration for your case. This is due to multiple reasons, for instance: Data Variability, Model Complexity, Computational Resources etc…
For example, if you want to train a Categorization AI that uses only the textual AI model distilbert-base-cased for 10 epochs with a batch size of 8, you can pass the following JSON object:
{
"document_classifier_config": {
"text_model_name": "distilbert-base-cased",
"image_model_name": null
},
"document_training_config": {
"n_epochs": 10,
"batch_size": 8
}
}
As to conclude, the Categorization AI parameters section allows you to customize the configuration of your Categorization AI. We recommend that you experiment with different configurations to find the optimal one for your case. The following is the full default JSON object that Konfuzio uses when you start a Categorization AI’s training:
{
"document_classifier_config": {
"text_model_name": "nbow",
"image_model_name": null
},
"document_training_config": {
"n_epochs": 20,
"batch_size": 1
}
}
For further technical details regarding the configuration of the Categorization AI, please refer to the Categorization AI developers documentation.
Project ID#
ID of the Project used in the REST API
Domain whitelist#
A list of newline-separated domains which are allowed to embed public Documents for this Project. Domains should be in lowercase and without protocol, i.e. “www.example.com”.
Page limit#
Maximum number of Pages per Document.
Auto-deletion of Documents#
Konfuzio allows the auto-deletion of Documents with dataset status equal to None. Example:
 To activate auto-deletion, you need to set
To activate auto-deletion, you need to set
auto_delete_documents_after_days to the number of days after which the Documents of this Project should be deleted.
You can set the value of this field using API and the user interface:
 By default, the value is empty, which turns auto-deletion off.
Once
By default, the value is empty, which turns auto-deletion off.
Once auto_delete_documents_after_days is set, the Konfuzio server will automatically delete Documents each day according to this rule.
Project Credentials#
Some custom AIs and marketplace AIs require the user to provide credentials to make them work. These credentials are usually used to access external services which provide specific functionality like making an API call to these services.
If your marketplace AI requires credentials, which will be noted in its description page, you can provide them in the Project Credentials section. These credentials are simple key/value pairs, where usually the key specifies what the credential is used for, and the value is usually a token or a password.
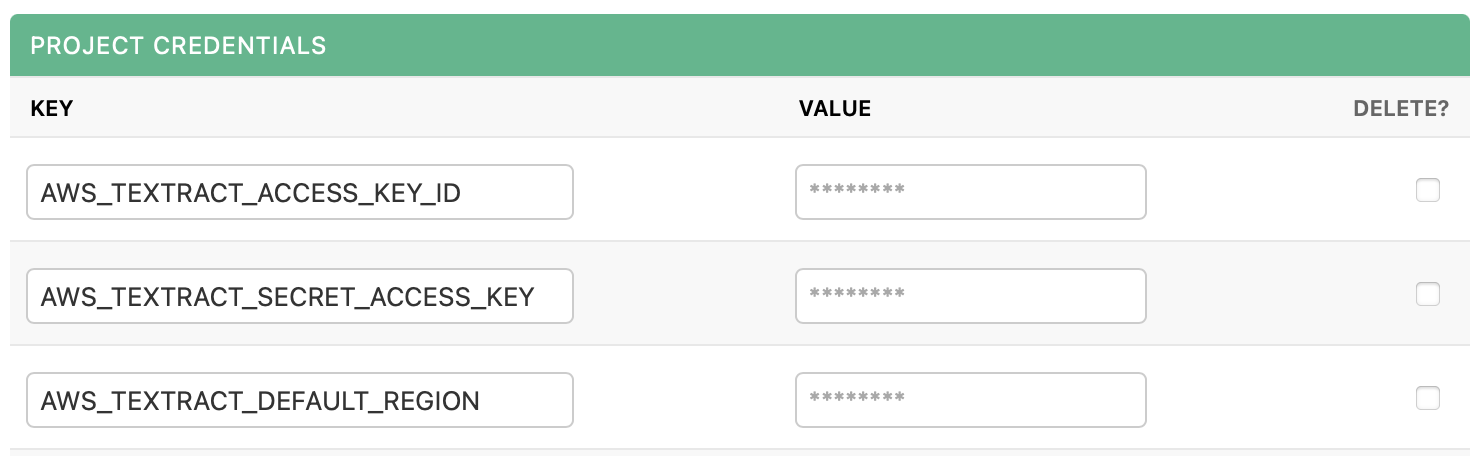
Credentials are stored securely on our server and the values cannot be edited or viewed by anyone once created. If you need to change a credential, you can delete it and create a new one with the same key.
Delete a Project#
Go to the List of Projects and select the Project you want to delete.
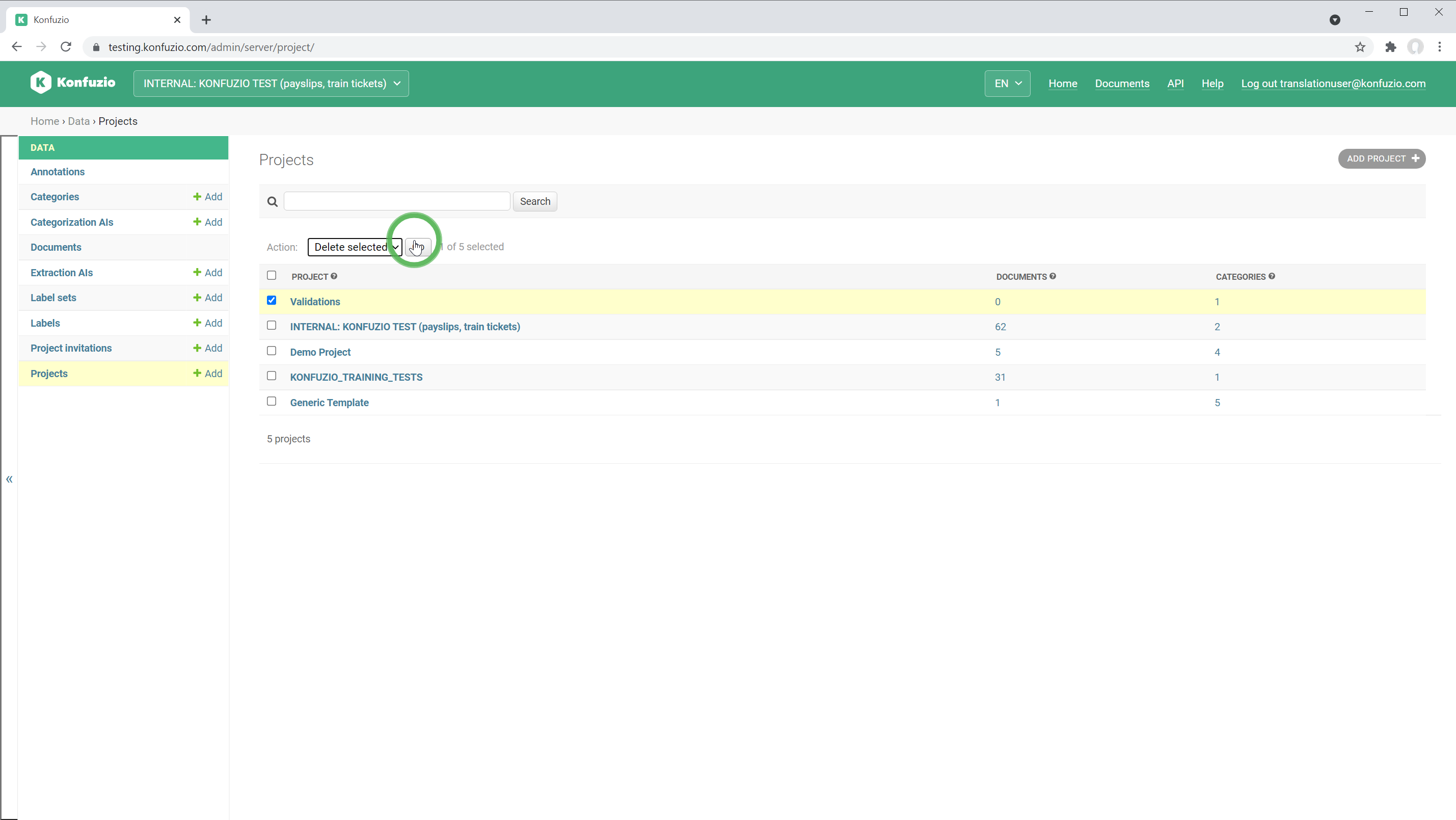
This will irreversibly delete all data of your Project. A Project can only be deleted if it has no Documents in the Project the dataset status of which is set to “Training” or “Test”.