Extraction AI#
Per category users can train Extraction AIs.
Users can activate one Extraction AI per category which will then be used to create Automated Annotations.
Extraction AI details#
Label Set#
Label Set in a Project used for training.
Status#
Statuses of an AI training:
“Queuing for training…”: The Extraction AI is waiting in the queue for its training to be started.
“Data loading in progress…”: The training process has started and the Konfuzio server loads the training data into memory.
“AI training in progress…”: The training data is loaded into memory and the actual training takes place.
“AI evaluation in progress…”: “The Extraction AI is trained and the evaluation of the trained Extraction AI is conducted.
“Training finished.”: The Extraction AI is evaluated and can be used.
In case the Extraction AI could not be trained it will have the status “Contact support”.
Description#
The description to document the reason for training.
Version#
The ordinal number of the AI trained for a given Category
AI Parameters#
Saved status of Extraction AI Parameters when training started.
Created At#
Date and time when training was started.
Loading time (in seconds):#
Displays the average, minimum and maximum loading time across all runs of this AI.
Runtime (in seconds):#
Displays the average, minimum and maximum runtime across all runs of this AI (If you add the loading and the runtime you get the overall time an AI run on a document has consumed).
Training Log#
The log file of the training task. This is useful for debugging purposes.
Evaluation Log#
The log file of the evaluation run. This is useful for debugging purposes.
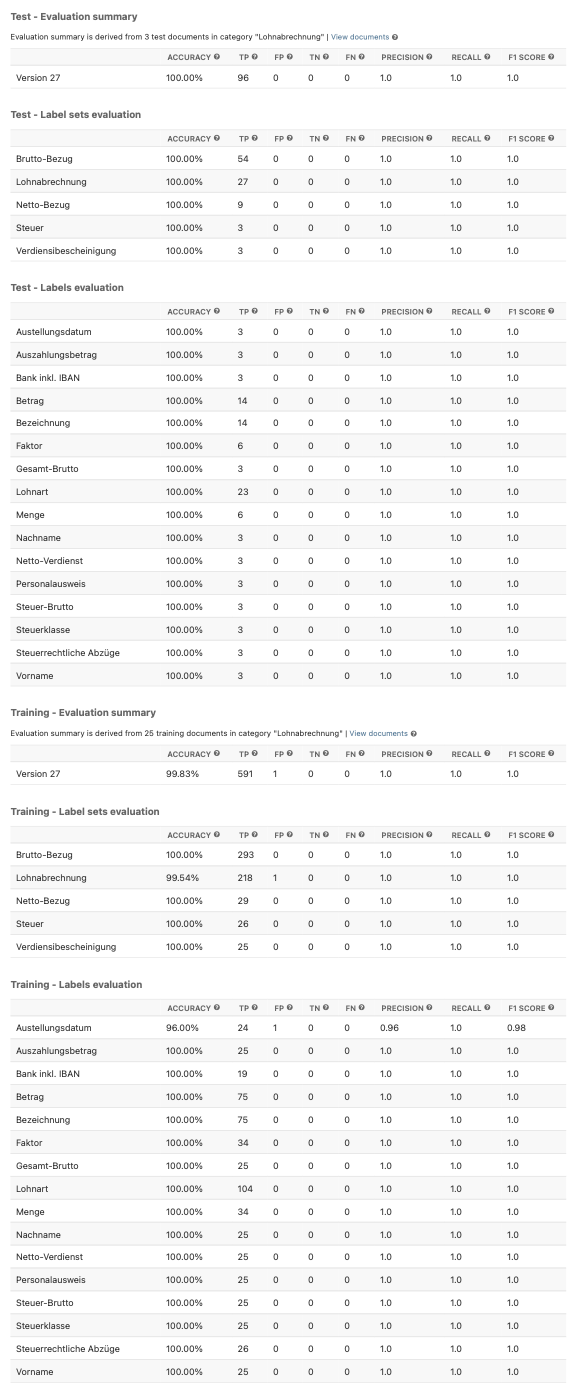
Evaluation#
AI quality evaluation on Category, Label Set and Label level. The evaluation is divided into separate sections for Training and Test dataset Documents.
Our evaluation process compares the extraction results of a predicted Document with the Annotations of the corresponding ground truth Document. We use the following criteria for counting True Positives (TP), False Positives (FP), and False Negatives (FN).
The criteria for the TP are the following:
There is an exact match in the predicted Annotation and the ground truth Annotation. In this case, partial matches are considered as TPs.
The predicted Annotation has the correct Label.
The predicted Annotation is correctly grouped into an Annotation Set with other predicted Annotations.
The Annotation Set of the predicted Annotation has a correctly predicted Label Set.
The confidence of the predicted Annotation is above threshold of a Label it received.
FN criteria:
If there is no match between the predicted Annotation and the ground truth Annotation, the ground truth Annotation counts as a FN because nothing was predicted for it.
If there is no Label predicted for the predicted Annotation, it counts as an FN.
If the predicted Annotation was predicted with too low confidence, it counts as an FN.
FP criteria:
If the predicted Annotation does not have an exact match to the ground truth Annotation, it counts as an FP.
If the predicted Annotation has an incorrect Label, it counts as an FP.
If the predicted Annotation was grouped into an Annotation Set incorrectly, it counts as an FP.
If the Annotation Set of the predicted Annotation has an incorrect Label Set, the Annotation counts as an FP.
Example: The predicted Annotation “12.2027” for the (6) Datum zu K Label does not exactly match the ground truth Annotation “08.12.2027”. In this case, the prediction “12.2027” counts as an FP, and the ground truth Annotation counts as an FN because there is no match to it in the predicted Document.
Ground Truth |
Prediction |
|---|---|
|
|


Example: The predicted Annotation “3.462,82” for the Auszahlungsbetrag Label matches exactly with the ground truth Annotation, therefore it counts as a TP.
Ground Truth |
Prediction |
|---|---|
|
|


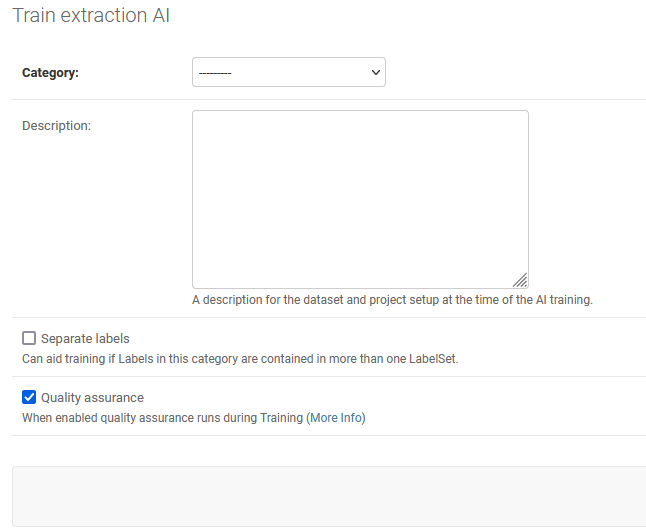
Train Extraction AI#
The training process is 100% automated, so the only setup users need to do is to select the Category for which an Extraction AI should be trained and add a short description. The short description will help to relate the intention behind any change in the project to the quality of the Extraction AI.
Visit the tutorial Improve Extraction AI to improve the quality of an Extraction AI.
Retrain Extraction AI#
If you have new Documents uploaded to your Project you can train a new version of your Extraction AI.
Add those to the Status: Training documents
Train Extraction AI, see above.
As you use the same Documents with Status: Test documents but increased the number of Documents with Status: Training documents the AI quality should improve.
Read more about how to Improve Extraction AI to improve your Extraction AI even further.
Extraction AI actions#
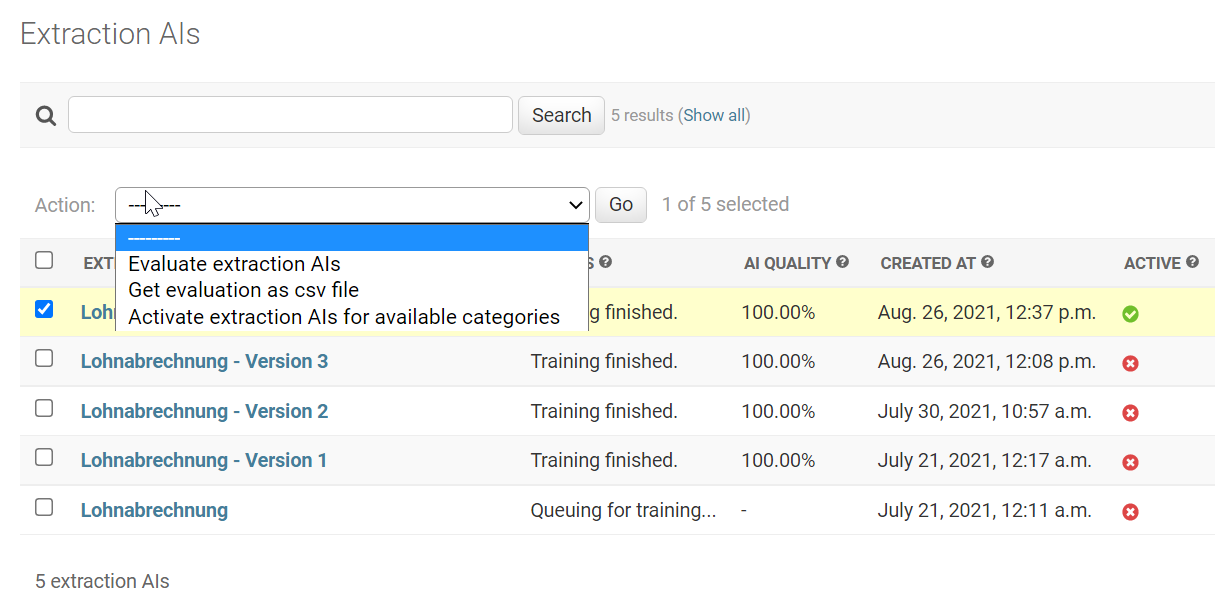
Evaluate Extraction AIs#
If you change the Documents assigned to the Test dataset you can evaluate old Extraction AI models. This is helpful to evaluate different Extraction AIs on the current test dataset.
Get evaluation as a CSV file#
Download the most granular evaluation file. Have a look at Improve Extraction AI to see how to use this CSV.
Activate Extraction AI for available Categories#
A handy option to update the Extraction AI for all related Categories, as multiple Categories can use one Extraction AI even across Projects.
Quality Assurance#
Quality Assurance is a Extraction AI setting which can be enabled while training an Extraction AI. By default this setting is disabled, but when enabled, the Documents contained within the Training and Test dataset will be evaluated for possible issues which may negatively impact the Extraction AI. Quality Assurance imposes high restrictions on the data handled and will attempt to fix any issue automatically. This setting is in place to ensure data consistency.
However, not all datasets will be repaired automatically. If training with Quality Assurance fails, please open a support a ticket and our team will come back with an estimate to improve the data quality manually.