Improve Extraction AI#
You have trained your first Extraction AI? Great, now we will support you to reach 90 % + accuracy.
Reaching high levels of accuracy will provide you with a trade-off. Either you invest time to review your training data over and over again vs. gaining accuracy by doing so. This tutorial does not only how you improve accuracy but also provides you with an indication of how much time you should plan to invest.
Prerequisites#
At any time make sure to check the following:
Ensure that you have an equal amount of Annotations per Label. In case one Label does not occur in every Document, an unequal distribution is understandable. If a Label appears less often it will be predicted with lower confidence in the beginning. The more Documents are added to training, the higher the confidence for this Label will become.
You should have more Status: Training documents than Status: Test documents, at least you need two.
Those checks will not improve the accuracy but create a solid base to improve the AI.
Extraction AI setup#
This step might feel surprising: reuploading a Document which was used by the AI to learn is the fastest procedure to check if the AI was properly trained.
When you reupload a Document from the training data, your expectation should be every Annotation you created manually should be recreated after upload. If this is not the case the structure of your AI seems to be inconsistent.
On the left side you see the Training Document; on the right side you see a copy of this Document newly uploaded.
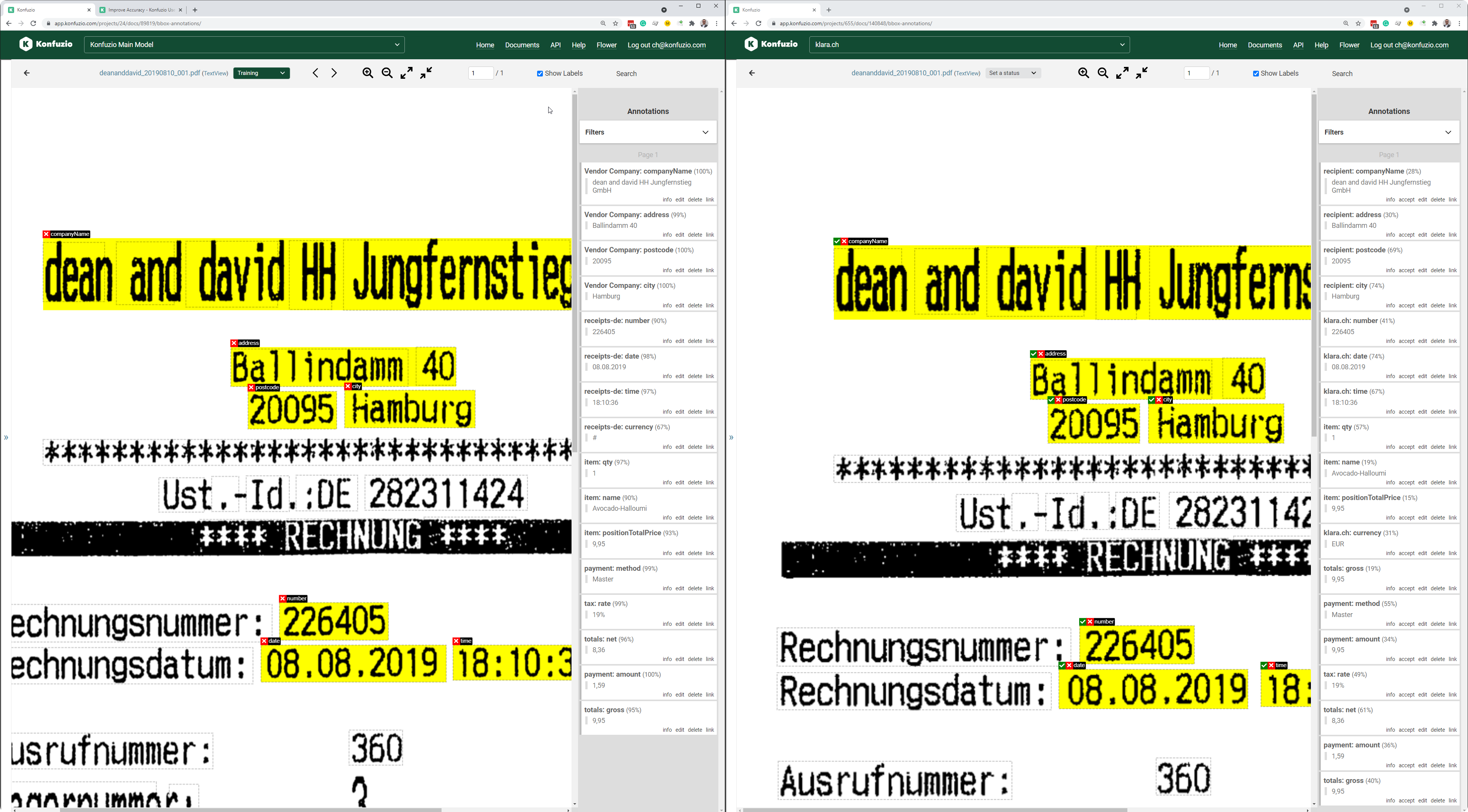
Make sure to see similar results as in the training data
When the model does not learn the structure you have labeled you need to review your Categories, Label Sets and Labels. Something seems to be wrong.
Background information#
The Konfuzio AI is not rule-based, but result-oriented. It considers the training data as the desired result and will set up rules for itself in order to apply them to new Documents and to try to achieve a corresponding result. In order for it to be able to recognize clear structures in this process, a clearly structured approach should also be taken during the manual labeling. Irregularities will cause the AI to search for rules and structures that do not exist, making it more difficult for it to make the right decisions.
The more uniform or homogeneous the Documents are among each other, the more accurate the results are. Standardized or normed Documents are optimal. However, this is usually not the case and is out of one’s control. In principle, this is not a problem for Konfuzio, but it means that the importance of the quality and quantity of the training data increases with the heterogeneity of the Documents.
Change the mode of Extraction#
Try to change from the Default “Word” to “Character” setup, see Detection mode of Extraction AI.
It is not for sure, but some users report they see an increase of performance of 10 % when switching to “Word based”.
Use automated Annotations#
Let’s assume you started with a small number of Labels you want to extract, e.g. gross amount and date. After a while you find out you need to label “VAT ID”, too.
What we see in this scenario is, users forget to add the new Label to Documents they have already labeled. The great thing is, once you have trained an AI you can “rerun” it on a Document. By doing so the model will suggest additional Annotations you did not yet create. The model will never overwrite Annotations you have created or revised manually.
For example, for monetary amounts in receipts, you should either always label the currency (e.g. the euro symbol) or always omit it. It does not matter which way you choose. It is important to do this consistently in all Documents and also within a Document. Of course, this also applies to other units such as kg, m2 etc. and other composite information.
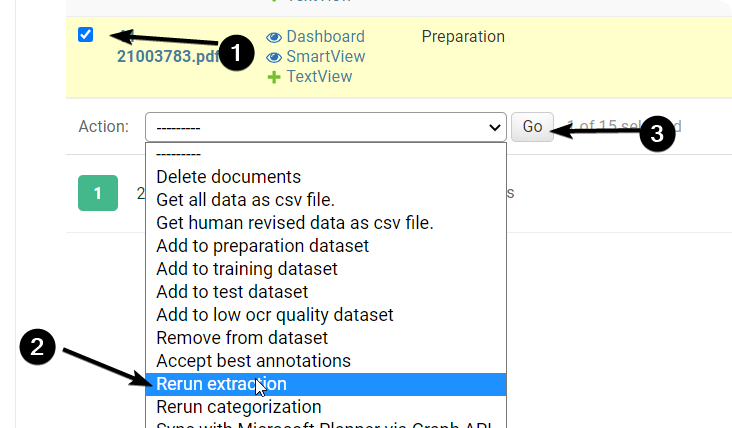
How to rerun a model:
Go to Documents and select the Documents
Select “Rerun extraction”
Press “Go” and wait for the Extraction to finish
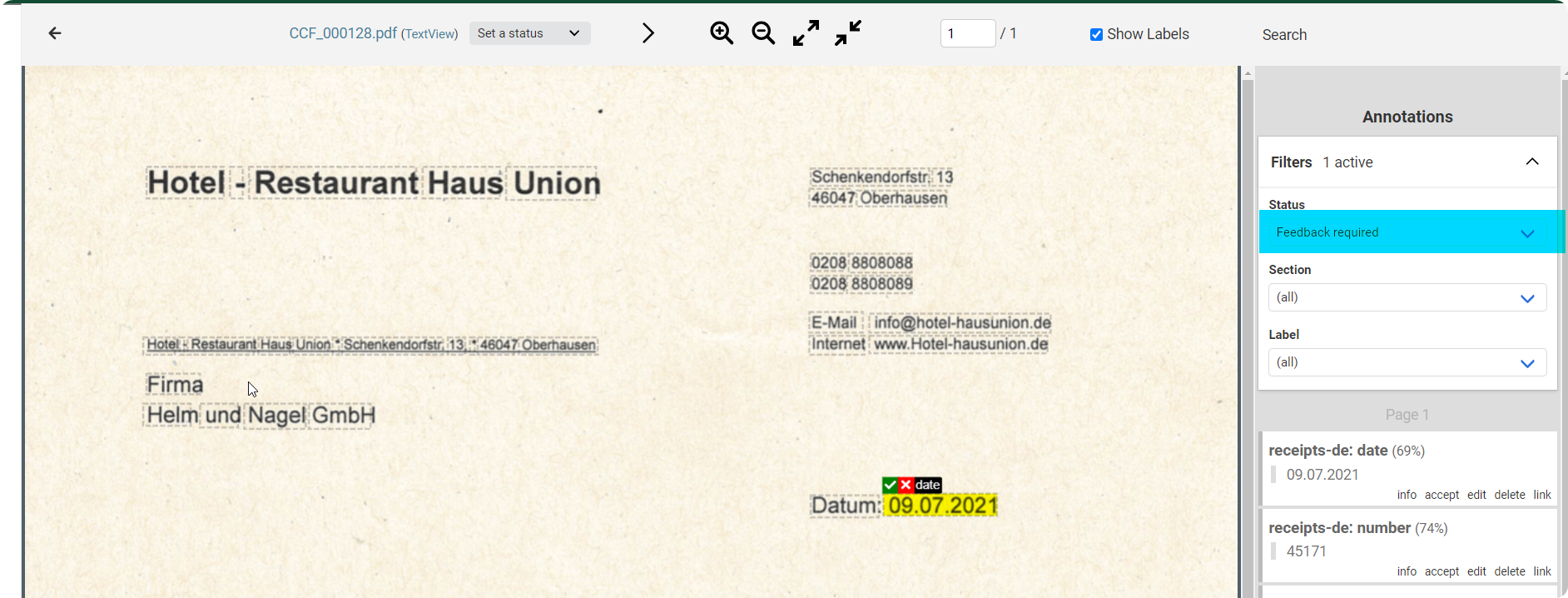
In case the model created new Annotations you will see their number as “Feedback required”.

Enter the Smartview and filter for “Feedback required” to review the Annotations created by your AI.
Background#
What if a value is printed on every Page?#
Let’s take the following example. All Pages of a Document type contain the date in the upper right corner. Does the date need to be marked on all Pages? In a Document with many Pages, this can become quite time-consuming. Typically, this is still done in the first Document, then in the second Document the date is marked on the first 3-4 Pages and in the third Document only on the first Page.
This is where the following problem occurs. The AI will look for a reason why the date on the 5th page of the first Document was relevant, but the one on the second Page of the third Document was not. But since there is no meaningful reason here, the AI will be “confused”, in human terms, which has a negative effect on the results. If you rerun the model on a Document you can see where the model would expect Annotations. To prevent confusion: either always label the repeating information on all Pages or always only on the first Page.
How does the evaluation treat values that appear multiple times?#
Often a Label can appear multiple times in a Document, say two to three times. The AI then recognizes the information in, say, two of the three places. I.e. the information was extracted correctly - but how is this taken into account in the evaluation?
With our current evaluation every single instance of the annotated information is being checked. So indeed, the score would be affected negatively. This change in our evaluation procedure is intentional and aimed at measuring further improvements to the AI in future versions of Konfuzio, with the goal of being able to extract all instances and only those instances.
How do I deal with class imbalance?#
In multi-class classification problems, the accuracy of the algorithm depends, among other things, on the balance of the different classes. If instances of one class occur very frequently compared to the other classes, they also enter more strongly into the error function that the algorithm tries to optimize. Accordingly, the algorithm may be incentivized to correctly predict the majority class, but pay less attention to the other classes.
There are two main scenarios.
For example, if some identification number appears at the top of every Page of the Document, and it’s always the same number, especially with similar format surrounding the text and layout of the identification number, this doesn’t produce a class imbalance in Konfuzio. Without going into too much detail, this is because one of the first steps in the Konfuzio algorithm is the detection (or tokenization) of an item, which happens independently, before classification, and which uses a Regex approach that doesn’t behave like the typical classifiers (see our blog post for the technical details).
An example where class imbalance can be a problem: if Label A has many more Annotations than Label B, and both labels have a lot of variance in their training Annotations (e.g. names of persons and companies which can have many different values, and for some reason there are many more person names in the Documents compared to company names).
Should I include punctuation?#
For consistency, it is important that when reading individual words from texts, commas, periods, brackets and other punctuation marks are not included. You should always mark only the actual content that you want to read. Punctuation marks usually come from the context of the sentence structure, but are rather arbitrary based on the training data and thus not suitable to be analyzed for the purpose of predictions. Otherwise, the AI will look for a comma at the end of the word to be read in the future, even if it has nothing to do with the information sought.
What if some Document layouts are rare in my training set?#
Should it be avoided to include a very rarely occurring Document layout in the AI training because it might have a negative impact on the model performance?
We usually find that new layouts will have a somewhat negative impact on model performance, when they are initially in low numbers in the training set. Gradually adding more can yield better results. In some cases, it may be a better idea to create a new Category for some new layouts. Various configurations have to be tried before the optimal one is found.
Automated confidence threshold search#
If you want to improve a particular Label’s extraction quality, you can modify its threshold to the one determined automatically by Konfuzio. The values for the optimal thresholds can be found on each Label’s page in a table. There are three thresholds: one to optimize for the best possible F1 score, one for the best precision and one for the best recall. Depending on your goals, you can choose either of them and replace the default 0.1 with it. Bear in mind that optimization for precision can result in a more conservative performance, less allowing for errors but more prone to generating False Negatives; optimization for recall is the opposite; and optimization for F1 score is balancing the two prior ones.
Sophisticated checks for Experts#
Download the Extraction AI model Evaluation, see .
1. Filter by False Positives (FP) with high Confidence#
FP are Annotations that the model predicts but are wrong. Most of the time there are two reasons for it. First, you forgot to label it. So the model will learn to predict them using some Documents in the Training Documents, but you forgot to label them in the other Documents. Second, you might have mislabeled Annotations. In case of a mislabeled Annotation the model is highly confident that the Label you applied to an Annotation is wrong, which then creates a FP.
To detect missing or mislabeled Annotations filter for all FP in the result column and sort by the “confidence” value:
Missing Annotations can cause FP with high Confidence most likely. If you see Annotations in this list, review those Documents by clicking on the link in column “link”.
Mislabeled Annotations can also be a cause of FP. Filter for all FP where the “offset_string” is equal to the “pred_offset_string”.
If you find a high number of False Positives where the “offset_string” is not equal to the “pred_offset_string” please try to change the AI model setup, see Change the mode of Extraction
Please contact us if you find a high number of Annotation if the “section_label” differs from the “pred_section_label”.
2. Filter by True Positives (TP) and sort by Confidence in ascending order#
TP are Annotations that the model predicted correctly. If you rank by Confidence, are there Annotations which have a low Confidence? The model was able to predict the Annotation correctly but with low confidence. There are two main reasons, why the confidence is low:
The number of examples in the Training documents is too low: You can review the number of Annotations per Label by visiting Home > Data > Labels. You will find a column “Training Annotations”. If the number of Annotations is unbalanced across Labels try to add more Documents to the training.
Labels are too similar or even relate to the same information: When multiple users work in the same Project it can happen that users create two Labels which refer to the same information but are named differently. The AI will be confused when to use which Label. Make your Labels refer to a unique piece of information. If you see Labels which refer to the same information but are named differently you need to delete the duplicated Label. Delete the Label with fewer Annotations, see Home > Data > Labels, and review all Documents again.
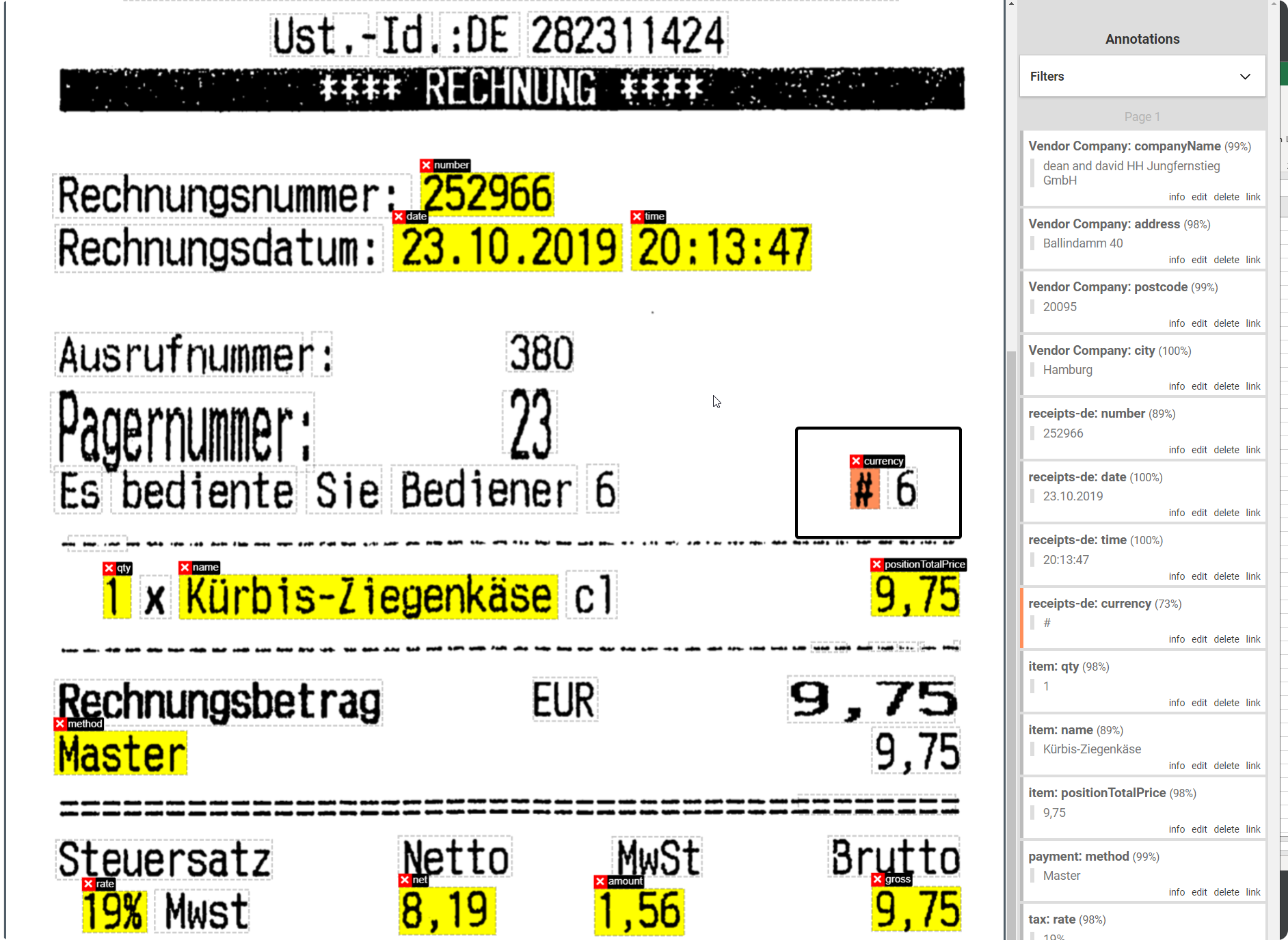
3. Filter by False Negatives (FN)#
FN are Annotations that the AI couldn’t predict. Please review your Annotations, most probably those Annotations are wrong. One example could be the “#” which is labeled as Currency.
4. Filter by Label#
If you suspect that some Label is using wrong training data, a quick way to verify it is to filter by Label and check the “offset_string” column. You can detect wrong Annotations by searching for outliers. For example, if you are only expecting numerical values for the Annotations of the Label “House Number” but you see a word in the “offset_string” column.