Tokenizers#
Introduction to Tokenizers#
Tokenizers are a powerful feature in Konfuzio that allows you to add and manage Tokenizers for specific Labels, enabling you to extract relevant information more accurately during AI Extraction. A Tokenizer is a tool that splits text into smaller pieces, called tokens, based on specific criteria. By using the Tokenizer feature to add and manage Tokenizers for your Label Sets, you can improve the accuracy of your Extraction AI.
To see this feature in action, please follow the following steps:
In a Project with a trained Extraction AI navigate to the section Label Set.
Click on any Label Set which has Labels.
Now you should be able to see Labels for this particular Label Set along with generated Tokenizers or the option to “Find Regexes” and generate these Tokenizers. If you are an on-premise Konfuzio user, you can also list all found Tokenizers in the left side-panel under Administration:Tokenizers.
“Find Regex” functionality#

Note: Regex, short for “regular expressions”, is a special text string used for pattern matching within text. Think of it like a secret code or a language that a computer can understand. It allows you to specify a set of rules or patterns that define how certain text should be recognized and treated. This can be incredibly useful for searching for specific patterns or data within a larger body of text, such as in the case of tokenizing text for Extraction AI.
The “Find Regex” functionality is a feature that allows you to determine the ideal regexes that can represent the underlying Label and creates the appropriate Tokenizer(s). This functionality can be used to help create Tokenizers for your Label Sets, and is automatically run during AI Extraction training on Labels that don’t have Tokenizers associated yet.
To use this functionality, go to the Label Set - Label page and click on the Label you want to create a Tokenizer for. On the Label page, click on the “Find Regex” button, and Konfuzio will automatically generate the appropriate regex for the Label.
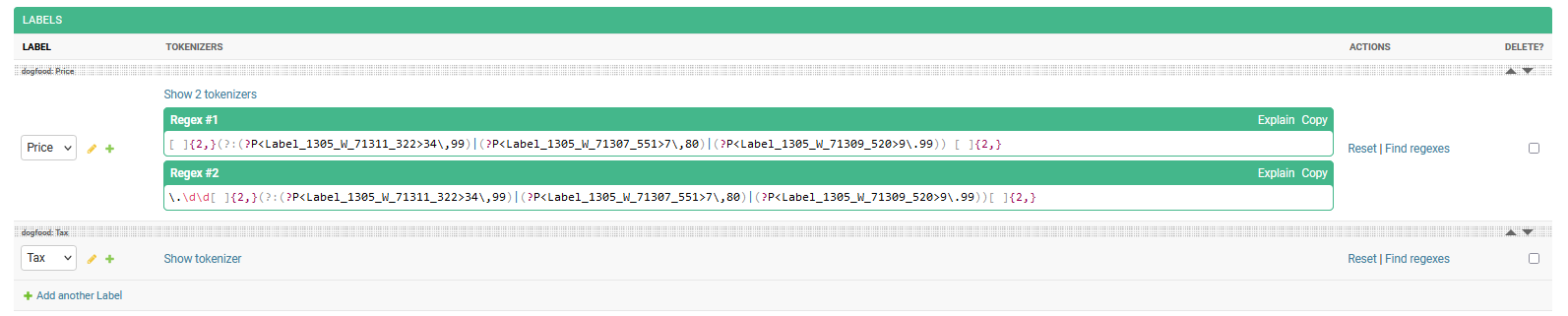
The generated Tokenizers can be found by clicking on the “Show Tokenizer” link.
Explain functionality#
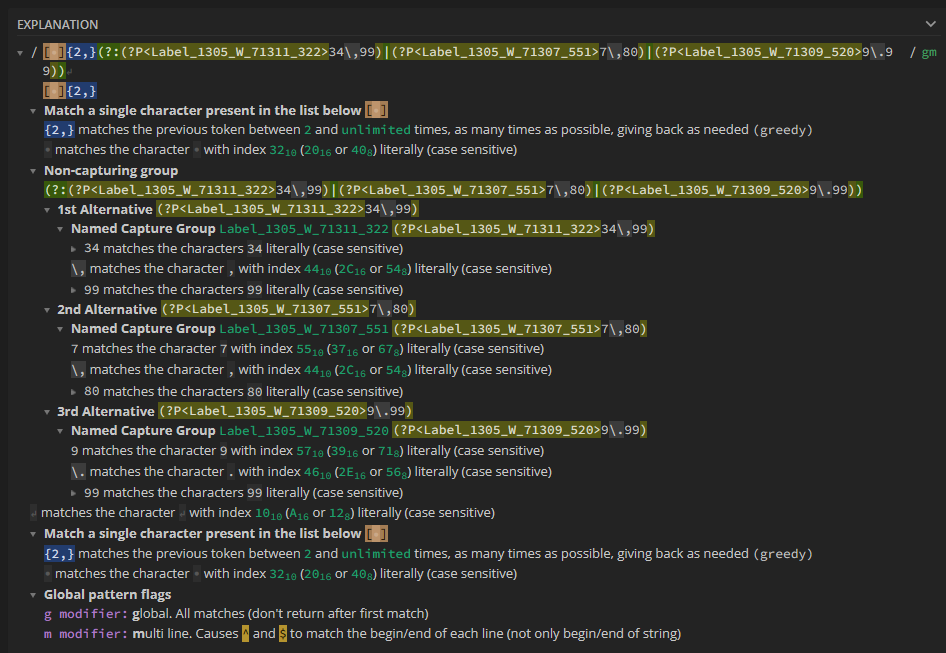
Each Tokenizer generated by the Find Regex functionality has an “Explain” link associated with it. Clicking on this link will send your generated Tokenizer to a third-party service called “regex101”. On the regex101 page, you can find detailed information about the regular expression associated with the Tokenizer, as well as a breakdown of its features. This can be useful for advanced users who want to further customize their Tokenizers and improve the accuracy of their Extraction AI.
Adding or editing regexes manually#
Adding or editing Tokenizers in Konfuzio is not possible due to the risk of regex-based denial of service (ReDoS) attacks. ReDoS exploits the fact that most regular expression implementations may reach extreme situations, causing them to work very slowly or even crash.
To protect our users and ensure their safety, Konfuzio has disabled the ability to add or edit Tokenizers manually. Instead, we recommend using the “Find Regex” functionality to generate appropriate regexes for your Label Sets automatically. This feature is designed to ensure the safety and security of our users while maintaining the high accuracy of Extraction AI.
More information about these concerns can be found here.
Label Set Label ordering#

The Tokenizer feature also allows you to order the Labels within your Label Sets. This functionality can be used to prioritize certain Labels and ensure that the relevant information is extracted in the correct order. To order your Label Sets by Labels, go to the Label Set page and click on the “Order Labels” button. You can then drag and drop the Labels into the desired order.
Annotation Tokenizer filter#
Tokenizers are associated with the Annotations that have been extracted to track which Tokenizer found which Annotation during Extraction. This enables you to understand which Annotations in the Documents cannot be found by any Tokenizer, and adjust your test and training dataset accordingly to improve your results.
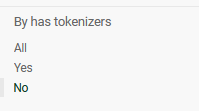
To view Annotations which have been extracted by a Tokenizer, and those which could not. You can go to the Annotations page, and filter by Tokenizer (All, Yes or No)